{"title":"Tree boosting methods for balanced and imbalanced classification and their robustness over time in risk assessment","authors":"Gissel Velarde , Michael Weichert, Anuj Deshmunkh, Sanjay Deshmane, Anindya Sudhir, Khushboo Sharma, Vaibhav Joshi","doi":"10.1016/j.iswa.2024.200354","DOIUrl":null,"url":null,"abstract":"<div><p>Most real-world classification problems deal with imbalanced datasets, posing a challenge for Artificial Intelligence (AI), i.e., machine learning algorithms, because the minority class, which is of extreme interest, often proves difficult to be detected. This paper empirically evaluates tree boosting methods' performance given different dataset sizes and class distributions, from perfectly balanced to highly imbalanced. For tabular data, tree-based methods such as XGBoost, stand out in several benchmarks due to detection performance and speed. Therefore, XGBoost and Imbalance-XGBoost are evaluated. After introducing the motivation to address risk assessment with machine learning, the paper reviews evaluation metrics for detection systems or binary classifiers. It proposes a method for data preparation followed by tree boosting methods including hyper-parameter optimization. The method is evaluated on private datasets of 1 thousand (K), 10K and 100K samples on distributions with 50, 45, 25, and 5 percent positive samples. As expected, the developed method increases its recognition performance as more data is given for training and the F1 score decreases as the data distribution becomes more imbalanced, but it is still significantly superior to the baseline of precision-recall determined by the ratio of positives divided by positives and negatives. Sampling to balance the training set does not provide consistent improvement and deteriorates detection. In contrast, classifier hyper-parameter optimization improves recognition, but should be applied carefully depending on data volume and distribution. Finally, the developed method is robust to data variation over time up to some point. Retraining can be used when performance starts deteriorating.</p></div>","PeriodicalId":100684,"journal":{"name":"Intelligent Systems with Applications","volume":"22 ","pages":"Article 200354"},"PeriodicalIF":0.0000,"publicationDate":"2024-03-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S2667305324000309/pdfft?md5=be6e208c32a749998c8ea1ee56dcab8e&pid=1-s2.0-S2667305324000309-main.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Intelligent Systems with Applications","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2667305324000309","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
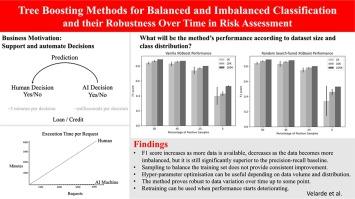
Most real-world classification problems deal with imbalanced datasets, posing a challenge for Artificial Intelligence (AI), i.e., machine learning algorithms, because the minority class, which is of extreme interest, often proves difficult to be detected. This paper empirically evaluates tree boosting methods' performance given different dataset sizes and class distributions, from perfectly balanced to highly imbalanced. For tabular data, tree-based methods such as XGBoost, stand out in several benchmarks due to detection performance and speed. Therefore, XGBoost and Imbalance-XGBoost are evaluated. After introducing the motivation to address risk assessment with machine learning, the paper reviews evaluation metrics for detection systems or binary classifiers. It proposes a method for data preparation followed by tree boosting methods including hyper-parameter optimization. The method is evaluated on private datasets of 1 thousand (K), 10K and 100K samples on distributions with 50, 45, 25, and 5 percent positive samples. As expected, the developed method increases its recognition performance as more data is given for training and the F1 score decreases as the data distribution becomes more imbalanced, but it is still significantly superior to the baseline of precision-recall determined by the ratio of positives divided by positives and negatives. Sampling to balance the training set does not provide consistent improvement and deteriorates detection. In contrast, classifier hyper-parameter optimization improves recognition, but should be applied carefully depending on data volume and distribution. Finally, the developed method is robust to data variation over time up to some point. Retraining can be used when performance starts deteriorating.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


