Shikha Yadav, Abdullah Mohammad Ghazi Al khatib, Bayan Mohamad Alshaib, Sushmita Ranjan, Binita Kumari, Naief Alabed Alkader, Pradeep Mishra, Promil Kapoor
{"title":"Decoding Potato Power: A Global Forecast of Production with Machine Learning and State-of-the-Art Techniques","authors":"Shikha Yadav, Abdullah Mohammad Ghazi Al khatib, Bayan Mohamad Alshaib, Sushmita Ranjan, Binita Kumari, Naief Alabed Alkader, Pradeep Mishra, Promil Kapoor","doi":"10.1007/s11540-024-09705-4","DOIUrl":null,"url":null,"abstract":"<p>As the second largest potato producer globally, reliable forecasts of output for India and major growing states are crucial. This study developed autoregressive integrated moving average (ARIMA) models alongside state space and gradient boosting machine learning techniques for annual potato production spanning 1967–2020. Model adequacy was evaluated using information criteria, errors metrics and out-of-sample validation. The chosen models provide the following forecasts: India is predicted to produce around 46,712 thousand metric tons, Uttar Pradesh 13,900 thousand metric tons, West Bengal 11,544 thousand metric tons, Bihar 7710 thousand metric tons, Madhya Pradesh 3478 thousand metric tons, Gujarat 3621 thousand metric tons and Punjab 2870 thousand metric tons over the period 2021–2027. While no consistent superior approach emerged, tailoring models to capture data complexity and patterns for each state proved essential for generalization. Quantitatively assessing linearity, stationarity and outliers during model specification is key for stakeholders and policymakers needing precise predictions.</p>","PeriodicalId":20378,"journal":{"name":"Potato Research","volume":"332 1","pages":""},"PeriodicalIF":2.1000,"publicationDate":"2024-02-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Potato Research","FirstCategoryId":"97","ListUrlMain":"https://doi.org/10.1007/s11540-024-09705-4","RegionNum":3,"RegionCategory":"农林科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"AGRONOMY","Score":null,"Total":0}
引用次数: 0
Abstract
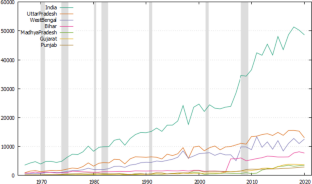
As the second largest potato producer globally, reliable forecasts of output for India and major growing states are crucial. This study developed autoregressive integrated moving average (ARIMA) models alongside state space and gradient boosting machine learning techniques for annual potato production spanning 1967–2020. Model adequacy was evaluated using information criteria, errors metrics and out-of-sample validation. The chosen models provide the following forecasts: India is predicted to produce around 46,712 thousand metric tons, Uttar Pradesh 13,900 thousand metric tons, West Bengal 11,544 thousand metric tons, Bihar 7710 thousand metric tons, Madhya Pradesh 3478 thousand metric tons, Gujarat 3621 thousand metric tons and Punjab 2870 thousand metric tons over the period 2021–2027. While no consistent superior approach emerged, tailoring models to capture data complexity and patterns for each state proved essential for generalization. Quantitatively assessing linearity, stationarity and outliers during model specification is key for stakeholders and policymakers needing precise predictions.
期刊介绍:
Potato Research, the journal of the European Association for Potato Research (EAPR), promotes the exchange of information on all aspects of this fast-evolving global industry. It offers the latest developments in innovative research to scientists active in potato research. The journal includes authoritative coverage of new scientific developments, publishing original research and review papers on such topics as:
Molecular sciences;
Breeding;
Physiology;
Pathology;
Nematology;
Virology;
Agronomy;
Engineering and Utilization.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


