{"title":"Leveraging Large Language Models for Clinical Abbreviation Disambiguation.","authors":"Manda Hosseini, Mandana Hosseini, Reza Javidan","doi":"10.1007/s10916-024-02049-z","DOIUrl":null,"url":null,"abstract":"<p><p>Clinical abbreviation disambiguation is a crucial task in the biomedical domain, as the accurate identification of the intended meanings or expansions of abbreviations in clinical texts is vital for medical information retrieval and analysis. Existing approaches have shown promising results, but challenges such as limited instances and ambiguous interpretations persist. In this paper, we propose an approach to address these challenges and enhance the performance of clinical abbreviation disambiguation. Our objective is to leverage the power of Large Language Models (LLMs) and employ a Generative Model (GM) to augment the dataset with contextually relevant instances, enabling more accurate disambiguation across diverse clinical contexts. We integrate the contextual understanding of LLMs, represented by BlueBERT and Transformers, with data augmentation using a Generative Model, called Biomedical Generative Pre-trained Transformer (BIOGPT), that is pretrained on an extensive corpus of biomedical literature to capture the intricacies of medical terminology and context. By providing the BIOGPT with relevant medical terms and sense information, we generate diverse instances of clinical text that accurately represent the intended meanings of abbreviations. We evaluate our approach on the widely recognized CASI dataset, carefully partitioned into training, validation, and test sets. The incorporation of data augmentation with the GM improves the model's performance, particularly for senses with limited instances, effectively addressing dataset imbalance and challenges posed by similar concepts. The results demonstrate the efficacy of our proposed method, showcasing the significance of LLMs and generative techniques in clinical abbreviation disambiguation. Our model achieves a good accuracy on the test set, outperforming previous methods.</p>","PeriodicalId":16338,"journal":{"name":"Journal of Medical Systems","volume":"48 1","pages":"27"},"PeriodicalIF":3.5000,"publicationDate":"2024-02-27","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Medical Systems","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1007/s10916-024-02049-z","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
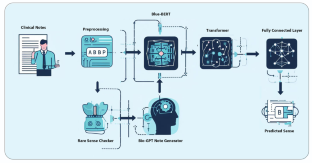
Abstract
Clinical abbreviation disambiguation is a crucial task in the biomedical domain, as the accurate identification of the intended meanings or expansions of abbreviations in clinical texts is vital for medical information retrieval and analysis. Existing approaches have shown promising results, but challenges such as limited instances and ambiguous interpretations persist. In this paper, we propose an approach to address these challenges and enhance the performance of clinical abbreviation disambiguation. Our objective is to leverage the power of Large Language Models (LLMs) and employ a Generative Model (GM) to augment the dataset with contextually relevant instances, enabling more accurate disambiguation across diverse clinical contexts. We integrate the contextual understanding of LLMs, represented by BlueBERT and Transformers, with data augmentation using a Generative Model, called Biomedical Generative Pre-trained Transformer (BIOGPT), that is pretrained on an extensive corpus of biomedical literature to capture the intricacies of medical terminology and context. By providing the BIOGPT with relevant medical terms and sense information, we generate diverse instances of clinical text that accurately represent the intended meanings of abbreviations. We evaluate our approach on the widely recognized CASI dataset, carefully partitioned into training, validation, and test sets. The incorporation of data augmentation with the GM improves the model's performance, particularly for senses with limited instances, effectively addressing dataset imbalance and challenges posed by similar concepts. The results demonstrate the efficacy of our proposed method, showcasing the significance of LLMs and generative techniques in clinical abbreviation disambiguation. Our model achieves a good accuracy on the test set, outperforming previous methods.
期刊介绍:
Journal of Medical Systems provides a forum for the presentation and discussion of the increasingly extensive applications of new systems techniques and methods in hospital clinic and physician''s office administration; pathology radiology and pharmaceutical delivery systems; medical records storage and retrieval; and ancillary patient-support systems. The journal publishes informative articles essays and studies across the entire scale of medical systems from large hospital programs to novel small-scale medical services. Education is an integral part of this amalgamation of sciences and selected articles are published in this area. Since existing medical systems are constantly being modified to fit particular circumstances and to solve specific problems the journal includes a special section devoted to status reports on current installations.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


