Julian Kauk, Helene Kreysa, André Scherag, Stefan R. Schweinberger
{"title":"The adaptive community-response (ACR) method for collecting misinformation on social media","authors":"Julian Kauk, Helene Kreysa, André Scherag, Stefan R. Schweinberger","doi":"10.1186/s40537-024-00894-w","DOIUrl":null,"url":null,"abstract":"<p>Social media can be a major accelerator of the spread of misinformation, thereby potentially compromising both individual well-being and social cohesion. Despite significant recent advances, the study of online misinformation is a relatively young field facing several (methodological) challenges. In this regard, the detection of online misinformation has proven difficult, as online large-scale data streams require (semi-)automated, highly specific and therefore sophisticated methods to separate posts containing misinformation from irrelevant posts. In the present paper, we introduce the adaptive community-response (ACR) method, an unsupervised technique for the large-scale collection of misinformation on Twitter (now known as ’X’). The ACR method is based on previous findings showing that Twitter users occasionally reply to misinformation with fact-checking by referring to specific fact-checking sites (crowdsourced fact-checking). In a first step, we captured such misinforming but fact-checked tweets. These tweets were used in a second step to extract specific linguistic features (keywords), enabling us to collect also those misinforming tweets that were not fact-checked at all as a third step. We initially present a mathematical framework of our method, followed by an explicit algorithmic implementation. We then evaluate ACR on the basis of a comprehensive dataset consisting of <span>\\(>25\\)</span> million tweets, belonging to <span>\\(>300\\)</span> misinforming stories. Our evaluation shows that ACR is a useful extension to the methods pool of the field, enabling researchers to collect online misinformation more comprehensively. Text similarity measures clearly indicated correspondence between the claims of false stories and the ACR tweets, even though ACR performance was heterogeneously distributed across the stories. A baseline comparison to the fact-checked tweets showed that the ACR method can detect story-related tweets to a comparable degree, while being sensitive to different types of tweets: Fact-checked tweets tend to be driven by high outreach (as indicated by a high number of retweets), whereas the sensitivity of the ACR method extends to tweets exhibiting lower outreach. Taken together, ACR’s capacity as a valuable methodological contribution to the field is based on (i) the adoption of prior, pioneering research in the field, (ii) a well-formalized mathematical framework and (iii) an empirical foundation via a comprehensive set of indicators.</p>","PeriodicalId":15158,"journal":{"name":"Journal of Big Data","volume":"130 1","pages":""},"PeriodicalIF":6.4000,"publicationDate":"2024-02-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Big Data","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1186/s40537-024-00894-w","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, THEORY & METHODS","Score":null,"Total":0}
引用次数: 0
Abstract
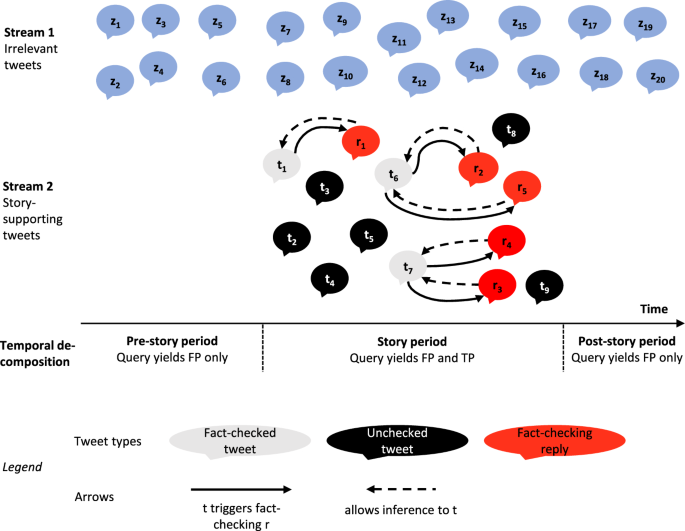
Social media can be a major accelerator of the spread of misinformation, thereby potentially compromising both individual well-being and social cohesion. Despite significant recent advances, the study of online misinformation is a relatively young field facing several (methodological) challenges. In this regard, the detection of online misinformation has proven difficult, as online large-scale data streams require (semi-)automated, highly specific and therefore sophisticated methods to separate posts containing misinformation from irrelevant posts. In the present paper, we introduce the adaptive community-response (ACR) method, an unsupervised technique for the large-scale collection of misinformation on Twitter (now known as ’X’). The ACR method is based on previous findings showing that Twitter users occasionally reply to misinformation with fact-checking by referring to specific fact-checking sites (crowdsourced fact-checking). In a first step, we captured such misinforming but fact-checked tweets. These tweets were used in a second step to extract specific linguistic features (keywords), enabling us to collect also those misinforming tweets that were not fact-checked at all as a third step. We initially present a mathematical framework of our method, followed by an explicit algorithmic implementation. We then evaluate ACR on the basis of a comprehensive dataset consisting of \(>25\) million tweets, belonging to \(>300\) misinforming stories. Our evaluation shows that ACR is a useful extension to the methods pool of the field, enabling researchers to collect online misinformation more comprehensively. Text similarity measures clearly indicated correspondence between the claims of false stories and the ACR tweets, even though ACR performance was heterogeneously distributed across the stories. A baseline comparison to the fact-checked tweets showed that the ACR method can detect story-related tweets to a comparable degree, while being sensitive to different types of tweets: Fact-checked tweets tend to be driven by high outreach (as indicated by a high number of retweets), whereas the sensitivity of the ACR method extends to tweets exhibiting lower outreach. Taken together, ACR’s capacity as a valuable methodological contribution to the field is based on (i) the adoption of prior, pioneering research in the field, (ii) a well-formalized mathematical framework and (iii) an empirical foundation via a comprehensive set of indicators.
期刊介绍:
The Journal of Big Data publishes high-quality, scholarly research papers, methodologies, and case studies covering a broad spectrum of topics, from big data analytics to data-intensive computing and all applications of big data research. It addresses challenges facing big data today and in the future, including data capture and storage, search, sharing, analytics, technologies, visualization, architectures, data mining, machine learning, cloud computing, distributed systems, and scalable storage. The journal serves as a seminal source of innovative material for academic researchers and practitioners alike.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


