{"title":"PLDE: A lightweight pooling layer for spoken language recognition","authors":"Zimu Li , Yanyan Xu , Dengfeng Ke , Kaile Su","doi":"10.1016/j.specom.2024.103055","DOIUrl":null,"url":null,"abstract":"<div><p>In recent years, the transfer learning method of replacing acoustic features with phonetic features has become a new paradigm for end-to-end spoken language recognition. However, these larger transfer learning models always encode too much redundant information. In this paper, we propose a lightweight language recognition decoder based on a phonetic learnable dictionary encoding (PLDE) layer, which is more suitable for phonetic features and achieves better recognition performances while significantly reducing the number of parameters. The lightweight decoder consists of three main parts: (1) a phonetic learnable dictionary with ghost clusters, which improves the traditional LDE pooling layer and enhances the model’s ability to model noise with ghost clusters; (2) coarse-grained chunk-level pooling, which can highlight the phone sequence and suppress noise around ghost clusters, and hence reduce their influence to the subsequent network; (3) fine-grained chunk-level projection, which enables the discriminative network to obtain more linguistic information and hence improve the model’s modelling ability. These three parts simplify the language recognition decoder into a PLDE pooling layer, reducing the parameter size of the decoder by at least one order of magnitude while achieving better recognition performances. In experiments on the OLR2020 dataset, the <span><math><msub><mrow><mi>C</mi></mrow><mrow><mi>a</mi><mi>v</mi><mi>g</mi></mrow></msub></math></span> of the proposed method exceeds that of the current state-of-the-art language recognition system, achieving 24.68% and 42.24% improvements on the cross-channel test set and unknown noise test set, respectively. Furthermore, experimental results on the OLR2021 dataset also demonstrate the effectiveness of PLDE.</p></div>","PeriodicalId":49485,"journal":{"name":"Speech Communication","volume":"158 ","pages":"Article 103055"},"PeriodicalIF":2.4000,"publicationDate":"2024-02-23","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Speech Communication","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S016763932400027X","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"ACOUSTICS","Score":null,"Total":0}
引用次数: 0
Abstract
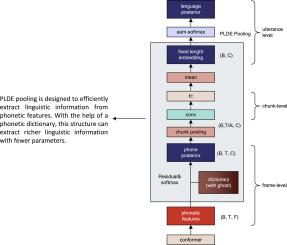
In recent years, the transfer learning method of replacing acoustic features with phonetic features has become a new paradigm for end-to-end spoken language recognition. However, these larger transfer learning models always encode too much redundant information. In this paper, we propose a lightweight language recognition decoder based on a phonetic learnable dictionary encoding (PLDE) layer, which is more suitable for phonetic features and achieves better recognition performances while significantly reducing the number of parameters. The lightweight decoder consists of three main parts: (1) a phonetic learnable dictionary with ghost clusters, which improves the traditional LDE pooling layer and enhances the model’s ability to model noise with ghost clusters; (2) coarse-grained chunk-level pooling, which can highlight the phone sequence and suppress noise around ghost clusters, and hence reduce their influence to the subsequent network; (3) fine-grained chunk-level projection, which enables the discriminative network to obtain more linguistic information and hence improve the model’s modelling ability. These three parts simplify the language recognition decoder into a PLDE pooling layer, reducing the parameter size of the decoder by at least one order of magnitude while achieving better recognition performances. In experiments on the OLR2020 dataset, the of the proposed method exceeds that of the current state-of-the-art language recognition system, achieving 24.68% and 42.24% improvements on the cross-channel test set and unknown noise test set, respectively. Furthermore, experimental results on the OLR2021 dataset also demonstrate the effectiveness of PLDE.
期刊介绍:
Speech Communication is an interdisciplinary journal whose primary objective is to fulfil the need for the rapid dissemination and thorough discussion of basic and applied research results.
The journal''s primary objectives are:
• to present a forum for the advancement of human and human-machine speech communication science;
• to stimulate cross-fertilization between different fields of this domain;
• to contribute towards the rapid and wide diffusion of scientifically sound contributions in this domain.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


