{"title":"Federated Freeze BERT for text classification","authors":"Omar Galal, Ahmed H. Abdel-Gawad, Mona Farouk","doi":"10.1186/s40537-024-00885-x","DOIUrl":null,"url":null,"abstract":"<p>Pre-trained BERT models have demonstrated exceptional performance in the context of text classification tasks. Certain problem domains necessitate data distribution without data sharing. Federated Learning (FL) allows multiple clients to collectively train a global model by sharing learned models rather than raw data. However, the adoption of BERT, a large model, within a Federated Learning framework incurs substantial communication costs. To address this challenge, we propose a novel framework, FedFreezeBERT, for BERT-based text classification. FedFreezeBERT works by adding an aggregation architecture on top of BERT to obtain better sentence embedding for classification while freezing BERT parameters. Keeping the model parameters frozen, FedFreezeBERT reduces the communication costs by a large factor compared to other state-of-the-art methods. FedFreezeBERT is implemented in a distributed version where the aggregation architecture only is being transferred and aggregated by FL algorithms such as FedAvg or FedProx. FedFreezeBERT is also implemented in a centralized version where the data embeddings extracted by BERT are sent to the central server to train the aggregation architecture. The experiments show that FedFreezeBERT achieves new state-of-the-art performance on Arabic sentiment analysis on the ArSarcasm-v2 dataset with a 12.9% and 1.2% improvement over FedAvg/FedProx and the previous SOTA respectively. FedFreezeBERT also reduces the communication cost by 5<span>\\(\\times\\)</span> compared to the previous SOTA.</p>","PeriodicalId":15158,"journal":{"name":"Journal of Big Data","volume":"21 1","pages":""},"PeriodicalIF":6.4000,"publicationDate":"2024-02-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Big Data","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1186/s40537-024-00885-x","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, THEORY & METHODS","Score":null,"Total":0}
引用次数: 0
Abstract
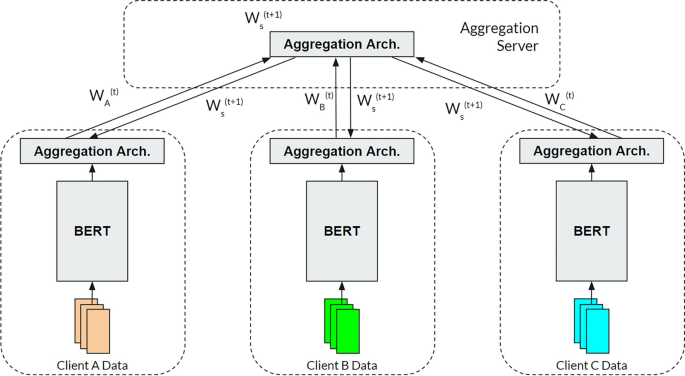
Pre-trained BERT models have demonstrated exceptional performance in the context of text classification tasks. Certain problem domains necessitate data distribution without data sharing. Federated Learning (FL) allows multiple clients to collectively train a global model by sharing learned models rather than raw data. However, the adoption of BERT, a large model, within a Federated Learning framework incurs substantial communication costs. To address this challenge, we propose a novel framework, FedFreezeBERT, for BERT-based text classification. FedFreezeBERT works by adding an aggregation architecture on top of BERT to obtain better sentence embedding for classification while freezing BERT parameters. Keeping the model parameters frozen, FedFreezeBERT reduces the communication costs by a large factor compared to other state-of-the-art methods. FedFreezeBERT is implemented in a distributed version where the aggregation architecture only is being transferred and aggregated by FL algorithms such as FedAvg or FedProx. FedFreezeBERT is also implemented in a centralized version where the data embeddings extracted by BERT are sent to the central server to train the aggregation architecture. The experiments show that FedFreezeBERT achieves new state-of-the-art performance on Arabic sentiment analysis on the ArSarcasm-v2 dataset with a 12.9% and 1.2% improvement over FedAvg/FedProx and the previous SOTA respectively. FedFreezeBERT also reduces the communication cost by 5\(\times\) compared to the previous SOTA.
期刊介绍:
The Journal of Big Data publishes high-quality, scholarly research papers, methodologies, and case studies covering a broad spectrum of topics, from big data analytics to data-intensive computing and all applications of big data research. It addresses challenges facing big data today and in the future, including data capture and storage, search, sharing, analytics, technologies, visualization, architectures, data mining, machine learning, cloud computing, distributed systems, and scalable storage. The journal serves as a seminal source of innovative material for academic researchers and practitioners alike.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


