Nazanin Moradinasab, Suchetha Sharma, Ronen Bar-Yoseph, Shlomit Radom-Aizik, Kenneth C. Bilchick, Dan M. Cooper, Arthur Weltman, Donald E. Brown
{"title":"Universal representation learning for multivariate time series using the instance-level and cluster-level supervised contrastive learning","authors":"Nazanin Moradinasab, Suchetha Sharma, Ronen Bar-Yoseph, Shlomit Radom-Aizik, Kenneth C. Bilchick, Dan M. Cooper, Arthur Weltman, Donald E. Brown","doi":"10.1007/s10618-024-01006-1","DOIUrl":null,"url":null,"abstract":"<p>The multivariate time series classification (MTSC) task aims to predict a class label for a given time series. Recently, modern deep learning-based approaches have achieved promising performance over traditional methods for MTSC tasks. The success of these approaches relies on access to the massive amount of labeled data (i.e., annotating or assigning tags to each sample that shows its corresponding category). However, obtaining a massive amount of labeled data is usually very time-consuming and expensive in many real-world applications such as medicine, because it requires domain experts’ knowledge to annotate data. Insufficient labeled data prevents these models from learning discriminative features, resulting in poor margins that reduce generalization performance. To address this challenge, we propose a novel approach: supervised contrastive learning for time series classification (SupCon-TSC). This approach improves the classification performance by learning the discriminative low-dimensional representations of multivariate time series, and its end-to-end structure allows for interpretable outcomes. It is based on supervised contrastive (SupCon) loss to learn the inherent structure of multivariate time series. First, two separate augmentation families, including strong and weak augmentation methods, are utilized to generate augmented data for the source and target networks, respectively. Second, we propose the instance-level, and cluster-level SupCon learning approaches to capture contextual information to learn the discriminative and universal representation for multivariate time series datasets. In the instance-level SupCon learning approach, for each given anchor instance that comes from the source network, the low-variance output encodings from the target network are sampled as positive and negative instances based on their labels. However, the cluster-level approach is performed between each instance and cluster centers among batches, as opposed to the instance-level approach. The cluster-level SupCon loss attempts to maximize the similarities between each instance and cluster centers among batches. We tested this novel approach on two small cardiopulmonary exercise testing (CPET) datasets and the real-world UEA Multivariate time series archive. The results of the SupCon-TSC model on CPET datasets indicate its capability to learn more discriminative features than existing approaches in situations where the size of the dataset is small. Moreover, the results on the UEA archive show that training a classifier on top of the universal representation features learned by our proposed method outperforms the state-of-the-art approaches.</p>","PeriodicalId":55183,"journal":{"name":"Data Mining and Knowledge Discovery","volume":"85 1","pages":""},"PeriodicalIF":2.8000,"publicationDate":"2024-02-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Data Mining and Knowledge Discovery","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10618-024-01006-1","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
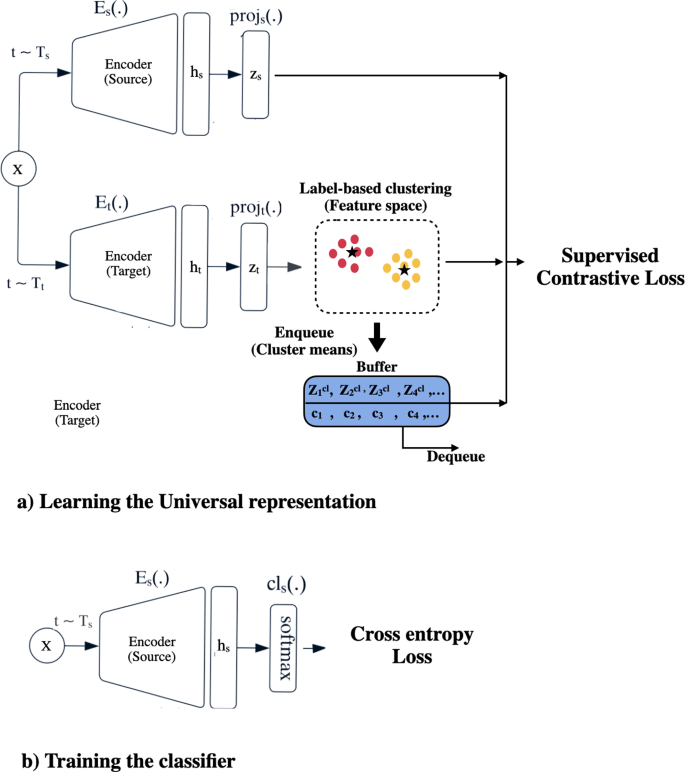
The multivariate time series classification (MTSC) task aims to predict a class label for a given time series. Recently, modern deep learning-based approaches have achieved promising performance over traditional methods for MTSC tasks. The success of these approaches relies on access to the massive amount of labeled data (i.e., annotating or assigning tags to each sample that shows its corresponding category). However, obtaining a massive amount of labeled data is usually very time-consuming and expensive in many real-world applications such as medicine, because it requires domain experts’ knowledge to annotate data. Insufficient labeled data prevents these models from learning discriminative features, resulting in poor margins that reduce generalization performance. To address this challenge, we propose a novel approach: supervised contrastive learning for time series classification (SupCon-TSC). This approach improves the classification performance by learning the discriminative low-dimensional representations of multivariate time series, and its end-to-end structure allows for interpretable outcomes. It is based on supervised contrastive (SupCon) loss to learn the inherent structure of multivariate time series. First, two separate augmentation families, including strong and weak augmentation methods, are utilized to generate augmented data for the source and target networks, respectively. Second, we propose the instance-level, and cluster-level SupCon learning approaches to capture contextual information to learn the discriminative and universal representation for multivariate time series datasets. In the instance-level SupCon learning approach, for each given anchor instance that comes from the source network, the low-variance output encodings from the target network are sampled as positive and negative instances based on their labels. However, the cluster-level approach is performed between each instance and cluster centers among batches, as opposed to the instance-level approach. The cluster-level SupCon loss attempts to maximize the similarities between each instance and cluster centers among batches. We tested this novel approach on two small cardiopulmonary exercise testing (CPET) datasets and the real-world UEA Multivariate time series archive. The results of the SupCon-TSC model on CPET datasets indicate its capability to learn more discriminative features than existing approaches in situations where the size of the dataset is small. Moreover, the results on the UEA archive show that training a classifier on top of the universal representation features learned by our proposed method outperforms the state-of-the-art approaches.
期刊介绍:
Advances in data gathering, storage, and distribution have created a need for computational tools and techniques to aid in data analysis. Data Mining and Knowledge Discovery in Databases (KDD) is a rapidly growing area of research and application that builds on techniques and theories from many fields, including statistics, databases, pattern recognition and learning, data visualization, uncertainty modelling, data warehousing and OLAP, optimization, and high performance computing.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


