Ziqian Yang, Hui Li, Renrong Ouyang, Quan Zhang, Jimin Xiao
{"title":"Multi-Keys Attention Network for Image Captioning","authors":"Ziqian Yang, Hui Li, Renrong Ouyang, Quan Zhang, Jimin Xiao","doi":"10.1007/s12559-023-10231-7","DOIUrl":null,"url":null,"abstract":"<p>The image captioning task aims to generate descriptions from the main content of images. Recently, the Transformer with a self-attention mechanism has been widely used for the image captioning task, where the attention mechanism helps the encoder to generate image region features, and guides caption output in the decoder. However, the vanilla decoder uses a simple conventional self-attention mechanism, resulting in captions with poor semantic information and incomplete sentence logic. In this paper, we propose a novel attention block, Multi-Keys attention block, that fully enhances the relevance between explicit and implicit semantic information. Technically, the Multi-Keys attention block first concatenates the key vector and the value vector and spreads it into both the explicit channel and the implicit channel. Then, the “related value” is generated with more semantic information by applying the element-wise multiplication to them. Moreover, to perfect the sentence logic, the reverse key vector with another information flow is residually connected to the final attention result. We also apply the Multi-Keys attention block into the sentence decoder in the transformer named as Multi-Keys Transformer (MKTrans). The experiments demonstrate that our MKTrans achieves 138.6% CIDEr score on MS COCO “Karpathy” offline test split. The proposed Multi-Keys attention block and MKTrans model are proven to be more effective and superior than the state-of-the-art methods.</p>","PeriodicalId":51243,"journal":{"name":"Cognitive Computation","volume":"9 1","pages":""},"PeriodicalIF":4.3000,"publicationDate":"2024-01-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Cognitive Computation","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s12559-023-10231-7","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
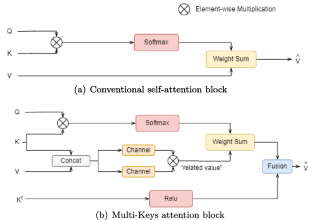
The image captioning task aims to generate descriptions from the main content of images. Recently, the Transformer with a self-attention mechanism has been widely used for the image captioning task, where the attention mechanism helps the encoder to generate image region features, and guides caption output in the decoder. However, the vanilla decoder uses a simple conventional self-attention mechanism, resulting in captions with poor semantic information and incomplete sentence logic. In this paper, we propose a novel attention block, Multi-Keys attention block, that fully enhances the relevance between explicit and implicit semantic information. Technically, the Multi-Keys attention block first concatenates the key vector and the value vector and spreads it into both the explicit channel and the implicit channel. Then, the “related value” is generated with more semantic information by applying the element-wise multiplication to them. Moreover, to perfect the sentence logic, the reverse key vector with another information flow is residually connected to the final attention result. We also apply the Multi-Keys attention block into the sentence decoder in the transformer named as Multi-Keys Transformer (MKTrans). The experiments demonstrate that our MKTrans achieves 138.6% CIDEr score on MS COCO “Karpathy” offline test split. The proposed Multi-Keys attention block and MKTrans model are proven to be more effective and superior than the state-of-the-art methods.
期刊介绍:
Cognitive Computation is an international, peer-reviewed, interdisciplinary journal that publishes cutting-edge articles describing original basic and applied work involving biologically-inspired computational accounts of all aspects of natural and artificial cognitive systems. It provides a new platform for the dissemination of research, current practices and future trends in the emerging discipline of cognitive computation that bridges the gap between life sciences, social sciences, engineering, physical and mathematical sciences, and humanities.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


