Unsupervised Clustering for a Comparative Methodology of Machine Learning Models to Detect Domain-Generated Algorithms Based on an Alphanumeric Features Analysis
IF 3.9 3区 计算机科学Q1 COMPUTER SCIENCE, INFORMATION SYSTEMS
{"title":"Unsupervised Clustering for a Comparative Methodology of Machine Learning Models to Detect Domain-Generated Algorithms Based on an Alphanumeric Features Analysis","authors":"Mohamed Hassaoui, Mohamed Hanini, Said El Kafhali","doi":"10.1007/s10922-023-09793-6","DOIUrl":null,"url":null,"abstract":"<p>Domain Generation Algorithms (DGAs) are often used for generating huge amounts of domain names to maintain command and control between the infected computer and the bot master. By establishing as needed a great number of domain names, attackers may mask their C2 servers and escape detection. Many malware families have switched to a stealthier contact approach. Therefore, the traditional methods become ineffective. Over the past decades, many researches have started to use artificial intelligence to create systems able to detect DGA in traffic, but these works do not use the same data to evaluate their models. This article proposes a comparative methodology to compare machine learning models based on unsupervised clustering and then applied this methodology to study the best models belonging to neural network methods and traditional machine learning methods to detect DGAs. We extracted 21 linguistic features based on the analysis of alphanumeric and n-gram, we studied the correlation between these features in order to reduce their number. We examine in detail those Machine learning algorithms and we discuss the drawbacks and strengths of each method with specific classes of DGA to propose a new switch case model that could be always reliable to detect DGAs.</p>","PeriodicalId":50119,"journal":{"name":"Journal of Network and Systems Management","volume":"10 1","pages":""},"PeriodicalIF":3.9000,"publicationDate":"2024-01-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Network and Systems Management","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10922-023-09793-6","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
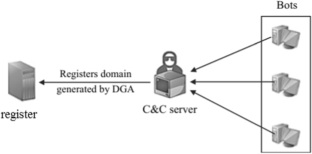
Domain Generation Algorithms (DGAs) are often used for generating huge amounts of domain names to maintain command and control between the infected computer and the bot master. By establishing as needed a great number of domain names, attackers may mask their C2 servers and escape detection. Many malware families have switched to a stealthier contact approach. Therefore, the traditional methods become ineffective. Over the past decades, many researches have started to use artificial intelligence to create systems able to detect DGA in traffic, but these works do not use the same data to evaluate their models. This article proposes a comparative methodology to compare machine learning models based on unsupervised clustering and then applied this methodology to study the best models belonging to neural network methods and traditional machine learning methods to detect DGAs. We extracted 21 linguistic features based on the analysis of alphanumeric and n-gram, we studied the correlation between these features in order to reduce their number. We examine in detail those Machine learning algorithms and we discuss the drawbacks and strengths of each method with specific classes of DGA to propose a new switch case model that could be always reliable to detect DGAs.
期刊介绍:
Journal of Network and Systems Management, features peer-reviewed original research, as well as case studies in the fields of network and system management. The journal regularly disseminates significant new information on both the telecommunications and computing aspects of these fields, as well as their evolution and emerging integration. This outstanding quarterly covers architecture, analysis, design, software, standards, and migration issues related to the operation, management, and control of distributed systems and communication networks for voice, data, video, and networked computing.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


