Marçal Comajoan Cara, Daniel Mas Montserrat, Alexander G Ioannidis
{"title":"PopGenAdapt: Semi-Supervised Domain Adaptation for Genotype-to-Phenotype Prediction in Underrepresented Populations.","authors":"Marçal Comajoan Cara, Daniel Mas Montserrat, Alexander G Ioannidis","doi":"","DOIUrl":null,"url":null,"abstract":"<p><p>The lack of diversity in genomic datasets, currently skewed towards individuals of European ancestry, presents a challenge in developing inclusive biomedical models. The scarcity of such data is particularly evident in labeled datasets that include genomic data linked to electronic health records. To address this gap, this paper presents PopGenAdapt, a genotype-to-phenotype prediction model which adopts semi-supervised domain adaptation (SSDA) techniques originally proposed for computer vision. PopGenAdapt is designed to leverage the substantial labeled data available from individuals of European ancestry, as well as the limited labeled and the larger amount of unlabeled data from currently underrepresented populations. The method is evaluated in underrepresented populations from Nigeria, Sri Lanka, and Hawaii for the prediction of several disease outcomes. The results suggest a significant improvement in the performance of genotype-to-phenotype models for these populations over state-of-the-art supervised learning methods, setting SSDA as a promising strategy for creating more inclusive machine learning models in biomedical research.Our code is available at https://github.com/AI-sandbox/PopGenAdapt.</p>","PeriodicalId":34954,"journal":{"name":"Pacific Symposium on Biocomputing. Pacific Symposium on Biocomputing","volume":"29 ","pages":"327-340"},"PeriodicalIF":0.0000,"publicationDate":"2024-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10906137/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Pacific Symposium on Biocomputing. Pacific Symposium on Biocomputing","FirstCategoryId":"1085","ListUrlMain":"","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"Computer Science","Score":null,"Total":0}
引用次数: 0
Abstract
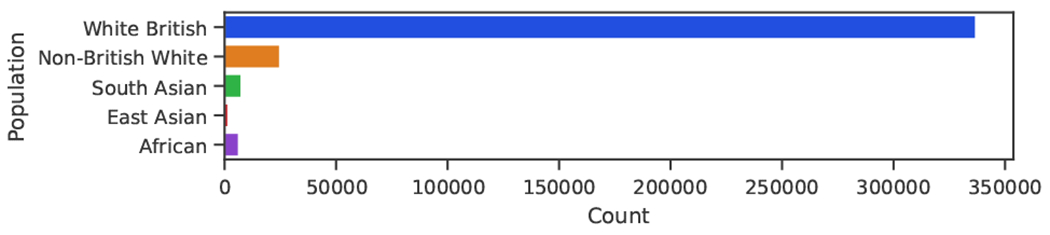
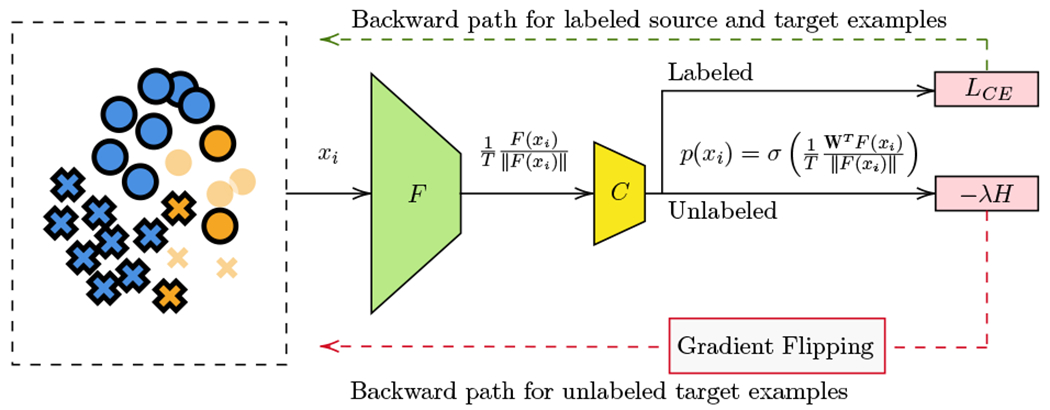
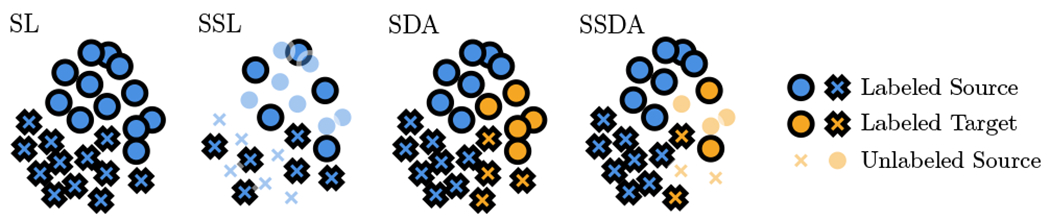
The lack of diversity in genomic datasets, currently skewed towards individuals of European ancestry, presents a challenge in developing inclusive biomedical models. The scarcity of such data is particularly evident in labeled datasets that include genomic data linked to electronic health records. To address this gap, this paper presents PopGenAdapt, a genotype-to-phenotype prediction model which adopts semi-supervised domain adaptation (SSDA) techniques originally proposed for computer vision. PopGenAdapt is designed to leverage the substantial labeled data available from individuals of European ancestry, as well as the limited labeled and the larger amount of unlabeled data from currently underrepresented populations. The method is evaluated in underrepresented populations from Nigeria, Sri Lanka, and Hawaii for the prediction of several disease outcomes. The results suggest a significant improvement in the performance of genotype-to-phenotype models for these populations over state-of-the-art supervised learning methods, setting SSDA as a promising strategy for creating more inclusive machine learning models in biomedical research.Our code is available at https://github.com/AI-sandbox/PopGenAdapt.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


