Hongchen Luo, Wei Zhai, Jing Zhang, Yang Cao, Dacheng Tao
{"title":"Grounded Affordance from Exocentric View","authors":"Hongchen Luo, Wei Zhai, Jing Zhang, Yang Cao, Dacheng Tao","doi":"10.1007/s11263-023-01962-z","DOIUrl":null,"url":null,"abstract":"<p>Affordance grounding aims to locate objects’ “action possibilities” regions, an essential step toward embodied intelligence. Due to the diversity of interactive affordance, <i>i.e.</i>, the uniqueness of different individual habits leads to diverse interactions, which makes it difficult to establish an explicit link between object parts and affordance labels. Human has the ability that transforms various exocentric interactions into invariant egocentric affordance to counter the impact of interactive diversity. To empower an agent with such ability, this paper proposes a task of affordance grounding from the exocentric view, <i>i.e.</i>, given exocentric human-object interaction and egocentric object images, learning the affordance knowledge of the object and transferring it to the egocentric image using only the affordance label as supervision. However, there is some “interaction bias” between personas, mainly regarding different regions and views. To this end, we devise a cross-view affordance knowledge transfer framework that extracts affordance-specific features from exocentric interactions and transfers them to the egocentric view to solve the above problems. Furthermore, the perception of affordance regions is enhanced by preserving affordance co-relations. In addition, an affordance grounding dataset named AGD20K is constructed by collecting and labeling over 20K images from 36 affordance categories. Experimental results demonstrate that our method outperforms the representative models regarding objective metrics and visual quality. The code is available via: github.com/lhc1224/Cross-View-AG.</p>","PeriodicalId":13752,"journal":{"name":"International Journal of Computer Vision","volume":"77 1","pages":""},"PeriodicalIF":11.6000,"publicationDate":"2023-12-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Computer Vision","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11263-023-01962-z","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
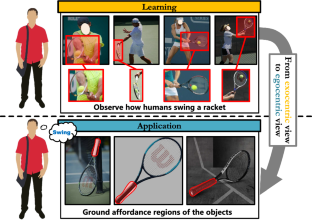
Affordance grounding aims to locate objects’ “action possibilities” regions, an essential step toward embodied intelligence. Due to the diversity of interactive affordance, i.e., the uniqueness of different individual habits leads to diverse interactions, which makes it difficult to establish an explicit link between object parts and affordance labels. Human has the ability that transforms various exocentric interactions into invariant egocentric affordance to counter the impact of interactive diversity. To empower an agent with such ability, this paper proposes a task of affordance grounding from the exocentric view, i.e., given exocentric human-object interaction and egocentric object images, learning the affordance knowledge of the object and transferring it to the egocentric image using only the affordance label as supervision. However, there is some “interaction bias” between personas, mainly regarding different regions and views. To this end, we devise a cross-view affordance knowledge transfer framework that extracts affordance-specific features from exocentric interactions and transfers them to the egocentric view to solve the above problems. Furthermore, the perception of affordance regions is enhanced by preserving affordance co-relations. In addition, an affordance grounding dataset named AGD20K is constructed by collecting and labeling over 20K images from 36 affordance categories. Experimental results demonstrate that our method outperforms the representative models regarding objective metrics and visual quality. The code is available via: github.com/lhc1224/Cross-View-AG.
期刊介绍:
The International Journal of Computer Vision (IJCV) serves as a platform for sharing new research findings in the rapidly growing field of computer vision. It publishes 12 issues annually and presents high-quality, original contributions to the science and engineering of computer vision. The journal encompasses various types of articles to cater to different research outputs.
Regular articles, which span up to 25 journal pages, focus on significant technical advancements that are of broad interest to the field. These articles showcase substantial progress in computer vision.
Short articles, limited to 10 pages, offer a swift publication path for novel research outcomes. They provide a quicker means for sharing new findings with the computer vision community.
Survey articles, comprising up to 30 pages, offer critical evaluations of the current state of the art in computer vision or offer tutorial presentations of relevant topics. These articles provide comprehensive and insightful overviews of specific subject areas.
In addition to technical articles, the journal also includes book reviews, position papers, and editorials by prominent scientific figures. These contributions serve to complement the technical content and provide valuable perspectives.
The journal encourages authors to include supplementary material online, such as images, video sequences, data sets, and software. This additional material enhances the understanding and reproducibility of the published research.
Overall, the International Journal of Computer Vision is a comprehensive publication that caters to researchers in this rapidly growing field. It covers a range of article types, offers additional online resources, and facilitates the dissemination of impactful research.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


