On a New Mixed Pareto–Weibull Distribution: Its Parametric Regression Model with an Insurance Applications
Abstract
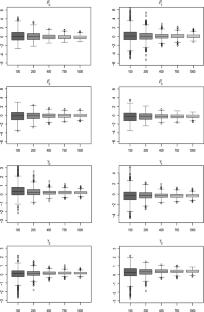
This article introduces a new probability distribution suitable for modeling heavy-tailed and right-skewed data sets. The proposed distribution is derived from the continuous mixture of the scale parameter of the Pareto family with the Weibull distribution. Analytical expressions for various distributional properties and actuarial risk measures of the proposed model are derived. The applicability of the proposed model is assessed using two real-world insurance data sets, and its performance is compared with the existing class of heavy-tailed models. The proposed model is assumed for the response variable in parametric regression modeling to account for the heterogeneity of individual policyholders. The Expectation-Maximization (EM) Algorithm is included to expedite the process of finding maximum likelihood (ML) estimates for the parameters of the proposed models. Real-world data application demonstrates that the proposed distribution performs well compared to its competitor models. The regression model utilizing the mixed Pareto–Weibull response distribution, characterized by regression structures for both the mean and dispersion parameters, demonstrates superior performance when compared to the Pareto–Weibull regression model, where the dispersion parameter depends on covariates.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


