{"title":"Classification of repeated measurements using bias corrected Euclidean distance discriminant function","authors":"Edward Kanuti Ngailo, Saralees Nadarajah","doi":"10.1007/s42952-023-00246-z","DOIUrl":null,"url":null,"abstract":"<p>This paper introduces a novel approach for approximating misclassification probabilities in Euclidean distance classifier when the group means exhibit a bilinear structure such as in the growth curve model first proposed by Potthoff and Roy (Biometrika 51:313–326, 1964). Initially, by leveraging certain statistical relationships, we establish two general results for the improved Euclidean discriminant function in both weighted and unweighted growth curve mean structures. We derive these approximations for the expected misclassification probabilities with respect to the distribution of the improved Euclidean discriminant function. Additionally, we compare the misclassification probabilities of the improved Euclidean discriminant function, the standard Euclidean discriminant function, and the linear discriminant function. It is important to note that in cases where the mean structure is weighted, a higher number of repeated measurements yields better classification results with the improved Euclidean discriminant function and the standard Euclidean discriminant function, allowing for more information to be acquired, as opposed to the linear discriminant function, which performs well with a smaller number of repeated measurements. Furthermore, we evaluate the accuracy of the suggested approximations by Monte Carlo simulations.</p>","PeriodicalId":49992,"journal":{"name":"Journal of the Korean Statistical Society","volume":"13 1","pages":""},"PeriodicalIF":0.8000,"publicationDate":"2023-12-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of the Korean Statistical Society","FirstCategoryId":"100","ListUrlMain":"https://doi.org/10.1007/s42952-023-00246-z","RegionNum":4,"RegionCategory":"数学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"STATISTICS & PROBABILITY","Score":null,"Total":0}
引用次数: 0
Abstract
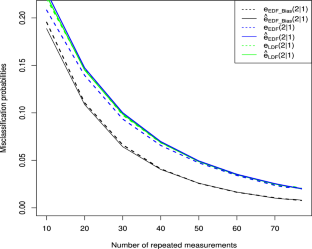
This paper introduces a novel approach for approximating misclassification probabilities in Euclidean distance classifier when the group means exhibit a bilinear structure such as in the growth curve model first proposed by Potthoff and Roy (Biometrika 51:313–326, 1964). Initially, by leveraging certain statistical relationships, we establish two general results for the improved Euclidean discriminant function in both weighted and unweighted growth curve mean structures. We derive these approximations for the expected misclassification probabilities with respect to the distribution of the improved Euclidean discriminant function. Additionally, we compare the misclassification probabilities of the improved Euclidean discriminant function, the standard Euclidean discriminant function, and the linear discriminant function. It is important to note that in cases where the mean structure is weighted, a higher number of repeated measurements yields better classification results with the improved Euclidean discriminant function and the standard Euclidean discriminant function, allowing for more information to be acquired, as opposed to the linear discriminant function, which performs well with a smaller number of repeated measurements. Furthermore, we evaluate the accuracy of the suggested approximations by Monte Carlo simulations.
期刊介绍:
The Journal of the Korean Statistical Society publishes research articles that make original contributions to the theory and methodology of statistics and probability. It also welcomes papers on innovative applications of statistical methodology, as well as papers that give an overview of current topic of statistical research with judgements about promising directions for future work. The journal welcomes contributions from all countries.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


