{"title":"FullStop: punctuation and segmentation prediction for Dutch with transformers","authors":"Vincent Vandeghinste, Oliver Guhr","doi":"10.1007/s10579-023-09676-x","DOIUrl":null,"url":null,"abstract":"<p>When applying automated speech recognition (ASR) for Belgian Dutch, the output consists of an unsegmented stream of words, without any punctuation. A next step is to perform segmentation and insert punctuation, making the ASR output more readable and easy to manually correct. We present the first (as far as we know) publicly available punctuation insertion system for Dutch that functions at a usable level and that is publicly available. The model we present here is an extension of the approach of Guhr et al. (In: Swiss Text Analytics Conference. Shared task on Sentence End and Punctuation Prediction in NLG Text, 2021) for Dutch: we finetuned the Dutch language model RobBERT on a punctuation prediction sequence classification task. The model was finetuned on two datasets: the Dutch side of Europarl and the SoNaR corpus. For every word in the input sequence, the model predicts a punctuation marker that follows the word. In cases where the language is unknown or where code switching applies, we have extended an existing multilingual model with Dutch. Previous work showed that such a multilingual model, based on “xlm-roberta-base” performs on par or sometimes even better than the monolingual cases. The system was evaluated on in-domain data as a classifier and on out-of-domain data as a sentence segmentation system through full stop prediction. The evaluations on sentence segmentation on out of domain data show that models finetuned on SoNaR show the best results, which can be attributed to SoNaR being a reference corpus containing different language registers. The multilingual models show an even better precision (at the cost of a lower recall) compared to the monolingual models.</p>","PeriodicalId":49927,"journal":{"name":"Language Resources and Evaluation","volume":"3 1","pages":""},"PeriodicalIF":1.8000,"publicationDate":"2023-07-14","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Language Resources and Evaluation","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10579-023-09676-x","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
Abstract
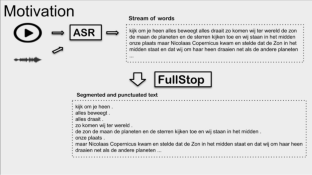
When applying automated speech recognition (ASR) for Belgian Dutch, the output consists of an unsegmented stream of words, without any punctuation. A next step is to perform segmentation and insert punctuation, making the ASR output more readable and easy to manually correct. We present the first (as far as we know) publicly available punctuation insertion system for Dutch that functions at a usable level and that is publicly available. The model we present here is an extension of the approach of Guhr et al. (In: Swiss Text Analytics Conference. Shared task on Sentence End and Punctuation Prediction in NLG Text, 2021) for Dutch: we finetuned the Dutch language model RobBERT on a punctuation prediction sequence classification task. The model was finetuned on two datasets: the Dutch side of Europarl and the SoNaR corpus. For every word in the input sequence, the model predicts a punctuation marker that follows the word. In cases where the language is unknown or where code switching applies, we have extended an existing multilingual model with Dutch. Previous work showed that such a multilingual model, based on “xlm-roberta-base” performs on par or sometimes even better than the monolingual cases. The system was evaluated on in-domain data as a classifier and on out-of-domain data as a sentence segmentation system through full stop prediction. The evaluations on sentence segmentation on out of domain data show that models finetuned on SoNaR show the best results, which can be attributed to SoNaR being a reference corpus containing different language registers. The multilingual models show an even better precision (at the cost of a lower recall) compared to the monolingual models.
期刊介绍:
Language Resources and Evaluation is the first publication devoted to the acquisition, creation, annotation, and use of language resources, together with methods for evaluation of resources, technologies, and applications.
Language resources include language data and descriptions in machine readable form used to assist and augment language processing applications, such as written or spoken corpora and lexica, multimodal resources, grammars, terminology or domain specific databases and dictionaries, ontologies, multimedia databases, etc., as well as basic software tools for their acquisition, preparation, annotation, management, customization, and use.
Evaluation of language resources concerns assessing the state-of-the-art for a given technology, comparing different approaches to a given problem, assessing the availability of resources and technologies for a given application, benchmarking, and assessing system usability and user satisfaction.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


