Xiaocong Chen, Siyu Wang, Lianyong Qi, Yong Li, Lina Yao
{"title":"Intrinsically motivated reinforcement learning based recommendation with counterfactual data augmentation","authors":"Xiaocong Chen, Siyu Wang, Lianyong Qi, Yong Li, Lina Yao","doi":"10.1007/s11280-023-01187-7","DOIUrl":null,"url":null,"abstract":"<p>Deep reinforcement learning (DRL) has shown promising results in modeling dynamic user preferences in RS in recent literature. However, training a DRL agent in the sparse RS environment poses a significant challenge. This is because the agent must balance between exploring informative user-item interaction trajectories and using existing trajectories for policy learning, a known exploration and exploitation trade-off. This trade-off greatly affects the recommendation performance when the environment is sparse. In DRL-based RS, balancing exploration and exploitation is even more challenging as the agent needs to deeply explore informative trajectories and efficiently exploit them in the context of RS. To address this issue, we propose a novel intrinsically motivated reinforcement learning (IMRL) method that enhances the agent’s capability to explore informative interaction trajectories in the sparse environment. We further enrich these trajectories via an adaptive counterfactual augmentation strategy with a customised threshold to improve their efficiency in exploitation. Our approach is evaluated on six offline datasets and three online simulation platforms, demonstrating its superiority over existing state-of-the-art methods. The extensive experiments show that our IMRL method outperforms other methods in terms of recommendation performance in the sparse RS environment.</p>","PeriodicalId":501180,"journal":{"name":"World Wide Web","volume":"41 3","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2023-07-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"1","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"World Wide Web","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s11280-023-01187-7","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 1
Abstract
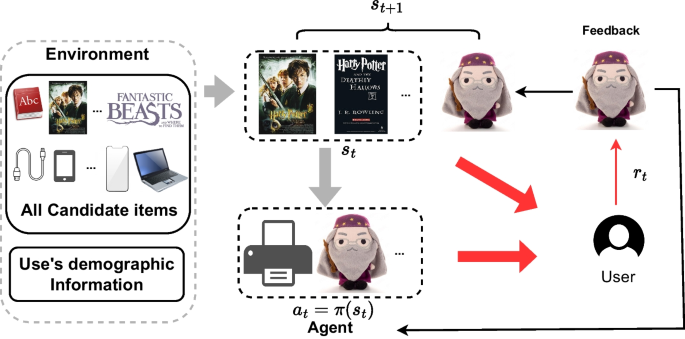
Deep reinforcement learning (DRL) has shown promising results in modeling dynamic user preferences in RS in recent literature. However, training a DRL agent in the sparse RS environment poses a significant challenge. This is because the agent must balance between exploring informative user-item interaction trajectories and using existing trajectories for policy learning, a known exploration and exploitation trade-off. This trade-off greatly affects the recommendation performance when the environment is sparse. In DRL-based RS, balancing exploration and exploitation is even more challenging as the agent needs to deeply explore informative trajectories and efficiently exploit them in the context of RS. To address this issue, we propose a novel intrinsically motivated reinforcement learning (IMRL) method that enhances the agent’s capability to explore informative interaction trajectories in the sparse environment. We further enrich these trajectories via an adaptive counterfactual augmentation strategy with a customised threshold to improve their efficiency in exploitation. Our approach is evaluated on six offline datasets and three online simulation platforms, demonstrating its superiority over existing state-of-the-art methods. The extensive experiments show that our IMRL method outperforms other methods in terms of recommendation performance in the sparse RS environment.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


