{"title":"CAE-GReaT: Convolutional-Auxiliary Efficient Graph Reasoning Transformer for Dense Image Predictions","authors":"Dong Zhang, Yi Lin, Jinhui Tang, Kwang-Ting Cheng","doi":"10.1007/s11263-023-01928-1","DOIUrl":null,"url":null,"abstract":"<p>Convolutional Neural Networks (CNNs) and Vision Transformer (ViT) are two primary frameworks for current semantic image recognition tasks in the community of computer vision. The general consensus is that both CNNs and ViT have their latent strengths and weaknesses, e.g., CNNs are good at extracting local features but difficult to aggregate long-range feature dependencies, while ViT is good at aggregating long-range feature dependencies but poorly represents in local features. In this paper, we propose an auxiliary and integrated network architecture, named Convolutional-Auxiliary Efficient Graph Reasoning Transformer (CAE-GReaT), which joints strengths of both CNNs and ViT into a uniform framework. CAE-GReaT stands on the shoulders of the advanced graph reasoning transformer and employs an internal auxiliary convolutional branch to enrich the local feature representations. Besides, to reduce the computational costs in graph reasoning, we also propose an efficient information diffusion strategy. Compared to the existing ViT models, CAE-GReaT not only has the advantage of a purposeful interaction pattern (<i>via the graph reasoning branch</i>), but also can capture fine-grained heterogeneous feature representations (<i>via the auxiliary convolutional branch</i>). Extensive experiments are implemented on three challenging dense image prediction tasks, i.e., semantic segmentation, instance segmentation, and panoptic segmentation. Results demonstrate that CAE-GReaT can achieve consistent performance gains on the state-of-the-art baselines with a slightly computational cost.</p>","PeriodicalId":13752,"journal":{"name":"International Journal of Computer Vision","volume":"83 21","pages":""},"PeriodicalIF":11.6000,"publicationDate":"2023-11-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Computer Vision","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11263-023-01928-1","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
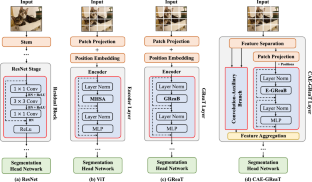
Convolutional Neural Networks (CNNs) and Vision Transformer (ViT) are two primary frameworks for current semantic image recognition tasks in the community of computer vision. The general consensus is that both CNNs and ViT have their latent strengths and weaknesses, e.g., CNNs are good at extracting local features but difficult to aggregate long-range feature dependencies, while ViT is good at aggregating long-range feature dependencies but poorly represents in local features. In this paper, we propose an auxiliary and integrated network architecture, named Convolutional-Auxiliary Efficient Graph Reasoning Transformer (CAE-GReaT), which joints strengths of both CNNs and ViT into a uniform framework. CAE-GReaT stands on the shoulders of the advanced graph reasoning transformer and employs an internal auxiliary convolutional branch to enrich the local feature representations. Besides, to reduce the computational costs in graph reasoning, we also propose an efficient information diffusion strategy. Compared to the existing ViT models, CAE-GReaT not only has the advantage of a purposeful interaction pattern (via the graph reasoning branch), but also can capture fine-grained heterogeneous feature representations (via the auxiliary convolutional branch). Extensive experiments are implemented on three challenging dense image prediction tasks, i.e., semantic segmentation, instance segmentation, and panoptic segmentation. Results demonstrate that CAE-GReaT can achieve consistent performance gains on the state-of-the-art baselines with a slightly computational cost.
期刊介绍:
The International Journal of Computer Vision (IJCV) serves as a platform for sharing new research findings in the rapidly growing field of computer vision. It publishes 12 issues annually and presents high-quality, original contributions to the science and engineering of computer vision. The journal encompasses various types of articles to cater to different research outputs.
Regular articles, which span up to 25 journal pages, focus on significant technical advancements that are of broad interest to the field. These articles showcase substantial progress in computer vision.
Short articles, limited to 10 pages, offer a swift publication path for novel research outcomes. They provide a quicker means for sharing new findings with the computer vision community.
Survey articles, comprising up to 30 pages, offer critical evaluations of the current state of the art in computer vision or offer tutorial presentations of relevant topics. These articles provide comprehensive and insightful overviews of specific subject areas.
In addition to technical articles, the journal also includes book reviews, position papers, and editorials by prominent scientific figures. These contributions serve to complement the technical content and provide valuable perspectives.
The journal encourages authors to include supplementary material online, such as images, video sequences, data sets, and software. This additional material enhances the understanding and reproducibility of the published research.
Overall, the International Journal of Computer Vision is a comprehensive publication that caters to researchers in this rapidly growing field. It covers a range of article types, offers additional online resources, and facilitates the dissemination of impactful research.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


