{"title":"Mimic before Reconstruct: Enhancing Masked Autoencoders with Feature Mimicking","authors":"Peng Gao, Ziyi Lin, Renrui Zhang, Rongyao Fang, Hongyang Li, Hongsheng Li, Yu Qiao","doi":"10.1007/s11263-023-01898-4","DOIUrl":null,"url":null,"abstract":"<p>Masked Autoencoders (MAE) have been popular paradigms for large-scale vision representation pre-training. However, MAE solely reconstructs the low-level RGB signals after the decoder and lacks supervision upon high-level semantics for the encoder, thus suffering from sub-optimal learned representations and long pre-training epochs. To alleviate this, previous methods simply replace the pixel reconstruction targets of 75% masked tokens by encoded features from pre-trained image-image (DINO) or image-language (CLIP) contrastive learning. Different from those efforts, we propose to <i>M</i>imic before <i>R</i>econstruct for Masked Autoencoders, named as <i>MR-MAE</i>, which jointly learns high-level and low-level representations without interference during pre-training. For high-level semantics, MR-MAE employs a mimic loss over 25% visible tokens from the encoder to capture the pre-trained patterns encoded in CLIP and DINO. For low-level structures, we inherit the reconstruction loss in MAE to predict RGB pixel values for 75% masked tokens after the decoder. As MR-MAE applies high-level and low-level targets respectively at different partitions, the learning conflicts between them can be naturally overcome and contribute to superior visual representations for various downstream tasks. On ImageNet-1K, the MR-MAE base pre-trained for only 400 epochs achieves 85.8% top-1 accuracy after fine-tuning, surpassing the 1600-epoch MAE base by <span>\\(+2.2\\)</span>% and the previous state-of-the-art BEiT V2 base by <span>\\(+0.3\\)</span>%. Pretrained checkpoints are released at https://github.com/Alpha-VL/ConvMAE.\n</p>","PeriodicalId":13752,"journal":{"name":"International Journal of Computer Vision","volume":"83 23","pages":""},"PeriodicalIF":11.6000,"publicationDate":"2023-11-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Computer Vision","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11263-023-01898-4","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
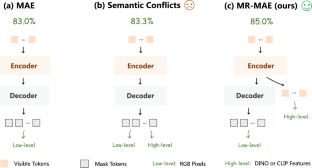
Masked Autoencoders (MAE) have been popular paradigms for large-scale vision representation pre-training. However, MAE solely reconstructs the low-level RGB signals after the decoder and lacks supervision upon high-level semantics for the encoder, thus suffering from sub-optimal learned representations and long pre-training epochs. To alleviate this, previous methods simply replace the pixel reconstruction targets of 75% masked tokens by encoded features from pre-trained image-image (DINO) or image-language (CLIP) contrastive learning. Different from those efforts, we propose to Mimic before Reconstruct for Masked Autoencoders, named as MR-MAE, which jointly learns high-level and low-level representations without interference during pre-training. For high-level semantics, MR-MAE employs a mimic loss over 25% visible tokens from the encoder to capture the pre-trained patterns encoded in CLIP and DINO. For low-level structures, we inherit the reconstruction loss in MAE to predict RGB pixel values for 75% masked tokens after the decoder. As MR-MAE applies high-level and low-level targets respectively at different partitions, the learning conflicts between them can be naturally overcome and contribute to superior visual representations for various downstream tasks. On ImageNet-1K, the MR-MAE base pre-trained for only 400 epochs achieves 85.8% top-1 accuracy after fine-tuning, surpassing the 1600-epoch MAE base by \(+2.2\)% and the previous state-of-the-art BEiT V2 base by \(+0.3\)%. Pretrained checkpoints are released at https://github.com/Alpha-VL/ConvMAE.
掩模自编码器(MAE)是一种流行的大规模视觉表征预训练方法。然而,MAE仅在解码器之后重建低级RGB信号,缺乏对编码器高级语义的监督,因此存在次优学习表征和较长的预训练时间。为了缓解这一问题,以前的方法只是简单地替换75的像素重建目标% masked tokens by encoded features from pre-trained image-image (DINO) or image-language (CLIP) contrastive learning. Different from those efforts, we propose to Mimic before Reconstruct for Masked Autoencoders, named as MR-MAE, which jointly learns high-level and low-level representations without interference during pre-training. For high-level semantics, MR-MAE employs a mimic loss over 25% visible tokens from the encoder to capture the pre-trained patterns encoded in CLIP and DINO. For low-level structures, we inherit the reconstruction loss in MAE to predict RGB pixel values for 75% masked tokens after the decoder. As MR-MAE applies high-level and low-level targets respectively at different partitions, the learning conflicts between them can be naturally overcome and contribute to superior visual representations for various downstream tasks. On ImageNet-1K, the MR-MAE base pre-trained for only 400 epochs achieves 85.8% top-1 accuracy after fine-tuning, surpassing the 1600-epoch MAE base by \(+2.2\)% and the previous state-of-the-art BEiT V2 base by \(+0.3\)%. Pretrained checkpoints are released at https://github.com/Alpha-VL/ConvMAE.
期刊介绍:
The International Journal of Computer Vision (IJCV) serves as a platform for sharing new research findings in the rapidly growing field of computer vision. It publishes 12 issues annually and presents high-quality, original contributions to the science and engineering of computer vision. The journal encompasses various types of articles to cater to different research outputs.
Regular articles, which span up to 25 journal pages, focus on significant technical advancements that are of broad interest to the field. These articles showcase substantial progress in computer vision.
Short articles, limited to 10 pages, offer a swift publication path for novel research outcomes. They provide a quicker means for sharing new findings with the computer vision community.
Survey articles, comprising up to 30 pages, offer critical evaluations of the current state of the art in computer vision or offer tutorial presentations of relevant topics. These articles provide comprehensive and insightful overviews of specific subject areas.
In addition to technical articles, the journal also includes book reviews, position papers, and editorials by prominent scientific figures. These contributions serve to complement the technical content and provide valuable perspectives.
The journal encourages authors to include supplementary material online, such as images, video sequences, data sets, and software. This additional material enhances the understanding and reproducibility of the published research.
Overall, the International Journal of Computer Vision is a comprehensive publication that caters to researchers in this rapidly growing field. It covers a range of article types, offers additional online resources, and facilitates the dissemination of impactful research.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


