{"title":"Adapting Across Domains via Target-Oriented Transferable Semantic Augmentation Under Prototype Constraint","authors":"Mixue Xie, Shuang Li, Kaixiong Gong, Yulin Wang, Gao Huang","doi":"10.1007/s11263-023-01944-1","DOIUrl":null,"url":null,"abstract":"<p>The demand for reducing label annotation cost and adapting to new data distributions gives rise to the emergence of domain adaptation (DA). DA aims to learn a model that performs well on the unlabeled or scarcely labeled target domain by transferring the rich knowledge from a related and well-annotated source domain. Existing DA methods mainly resort to learning domain-invariant representations with a source-supervised classifier shared by two domains. However, such a shared classifier may bias towards source domain, limiting its generalization capability on target data. To alleviate this issue, we present a <i>target-oriented transferable semantic augmentation (T</i><span>\\(^2\\)</span><i>SA)</i> method, which enhances the generalization ability of the classifier by training it with a target-like augmented domain, constructed by semantically augmenting source data towards target at the feature level in an implicit manner. Specifically, to equip the augmented domain with target semantics, we delicately design a class-wise multivariate normal distribution based on the statistics estimated from features to sample the transformation directions for source data. Moreover, we achieve the augmentation implicitly by minimizing the upper bound of the expected Angular-softmax loss over the augmented domain, which is of high efficiency. Additionally, to further ensure that the augmented domain can imitate target domain nicely and discriminatively, the prototype constraint is enforced on augmented features class-wisely, which minimizes the expected distance between augmented features and corresponding target prototype (i.e., average representation) in Euclidean space. As a general technique, T<span>\\(^2\\)</span>SA can be easily plugged into various DA methods to further boost their performances. Extensive experiments under single-source DA, multi-source DA and domain generalization scenarios validate the efficacy of T<span>\\(^2\\)</span>SA.</p>","PeriodicalId":13752,"journal":{"name":"International Journal of Computer Vision","volume":"83 19","pages":""},"PeriodicalIF":11.6000,"publicationDate":"2023-11-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Computer Vision","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11263-023-01944-1","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
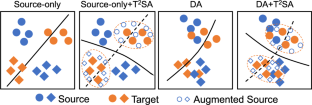
The demand for reducing label annotation cost and adapting to new data distributions gives rise to the emergence of domain adaptation (DA). DA aims to learn a model that performs well on the unlabeled or scarcely labeled target domain by transferring the rich knowledge from a related and well-annotated source domain. Existing DA methods mainly resort to learning domain-invariant representations with a source-supervised classifier shared by two domains. However, such a shared classifier may bias towards source domain, limiting its generalization capability on target data. To alleviate this issue, we present a target-oriented transferable semantic augmentation (T\(^2\)SA) method, which enhances the generalization ability of the classifier by training it with a target-like augmented domain, constructed by semantically augmenting source data towards target at the feature level in an implicit manner. Specifically, to equip the augmented domain with target semantics, we delicately design a class-wise multivariate normal distribution based on the statistics estimated from features to sample the transformation directions for source data. Moreover, we achieve the augmentation implicitly by minimizing the upper bound of the expected Angular-softmax loss over the augmented domain, which is of high efficiency. Additionally, to further ensure that the augmented domain can imitate target domain nicely and discriminatively, the prototype constraint is enforced on augmented features class-wisely, which minimizes the expected distance between augmented features and corresponding target prototype (i.e., average representation) in Euclidean space. As a general technique, T\(^2\)SA can be easily plugged into various DA methods to further boost their performances. Extensive experiments under single-source DA, multi-source DA and domain generalization scenarios validate the efficacy of T\(^2\)SA.
期刊介绍:
The International Journal of Computer Vision (IJCV) serves as a platform for sharing new research findings in the rapidly growing field of computer vision. It publishes 12 issues annually and presents high-quality, original contributions to the science and engineering of computer vision. The journal encompasses various types of articles to cater to different research outputs.
Regular articles, which span up to 25 journal pages, focus on significant technical advancements that are of broad interest to the field. These articles showcase substantial progress in computer vision.
Short articles, limited to 10 pages, offer a swift publication path for novel research outcomes. They provide a quicker means for sharing new findings with the computer vision community.
Survey articles, comprising up to 30 pages, offer critical evaluations of the current state of the art in computer vision or offer tutorial presentations of relevant topics. These articles provide comprehensive and insightful overviews of specific subject areas.
In addition to technical articles, the journal also includes book reviews, position papers, and editorials by prominent scientific figures. These contributions serve to complement the technical content and provide valuable perspectives.
The journal encourages authors to include supplementary material online, such as images, video sequences, data sets, and software. This additional material enhances the understanding and reproducibility of the published research.
Overall, the International Journal of Computer Vision is a comprehensive publication that caters to researchers in this rapidly growing field. It covers a range of article types, offers additional online resources, and facilitates the dissemination of impactful research.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


