On understanding and predicting issue links
IF 3.3
3区 计算机科学
Q3 COMPUTER SCIENCE, INFORMATION SYSTEMS
引用次数: 0
Abstract
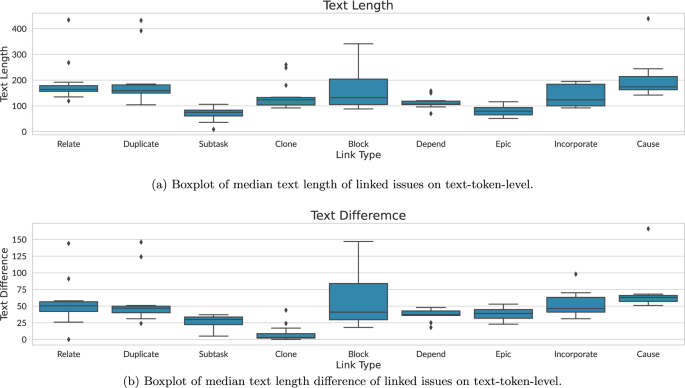
Abstract Stakeholders in software projects use issue trackers like JIRA or Bugzilla to capture and manage issues, including requirements, feature requests, and bugs. To ease issue navigation and structure project knowledge, stakeholders manually connect issues via links of certain types that reflect different dependencies, such as Epic-, Block-, Duplicate-, or Relate- links. Based on a large dataset of 16 JIRA repositories, we study the commonalities and differences in linking practices and link types across the repositories. We then investigate how state-of-the-art machine learning models can predict common link types. We observed significant differences across the repositories and link types, depending on how they are used and by whom. Additionally, we observed several inconsistencies, e.g., in how Duplicate links are used. We found that a transformer model trained on titles and descriptions of linked issues significantly outperforms other optimized models, achieving an encouraging average macro F1-score of 0.64 for predicting nine popular link types across all repositories (weighted F1-score of 0.73). For the specific Subtask- and Epic- links, the model achieves top F1-scores of 0.89 and 0.97, respectively. If we restrict the task to predict the mere existence of links, the average macro F1-score goes up to 0.95. In general, the shorter issue text, possibly indicating precise issues, seems to improve the prediction accuracy with a strong negative correlation of $$-$$
关于理解和预测问题环节
软件项目中的涉众使用JIRA或Bugzilla之类的问题跟踪器来捕获和管理问题,包括需求、特性请求和bug。为了简化问题导航和构建项目知识,涉众通过反映不同依赖关系的特定类型的链接手动连接问题,例如Epic-、Block-、Duplicate-或Relate-链接。基于16个JIRA存储库的大型数据集,我们研究了存储库之间链接实践和链接类型的共性和差异。然后,我们研究了最先进的机器学习模型如何预测常见的链接类型。我们观察到存储库和链接类型之间的显著差异,这取决于它们的使用方式和用户。此外,我们还观察到一些不一致之处,例如,重复链接的使用方式。我们发现,对关联问题的标题和描述进行训练的转换模型明显优于其他优化模型,在预测所有存储库中的9种流行链接类型(加权f1得分为0.73)方面,实现了令人鼓舞的平均宏观f1得分0.64。对于特定的Subtask-和Epic-链接,该模型分别达到了0.89和0.97的最高f1分数。如果我们将任务限制为预测链接的存在,平均宏观f1得分上升到0.95。一般来说,较短的问题文本(可能表示精确的问题)似乎提高了预测的准确性,其负相关关系为$$-$$ - 0.73。我们发现关联链接经常与其他链接混淆,这表明它们可能在不明确的情况下被用作默认链接。我们的发现,特别是在问题链接数据的质量和异质性方面,对问题链接预测的研究和应用具有重要意义。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Requirements Engineering
工程技术-计算机:软件工程
CiteScore
7.10
自引率
10.70%
发文量
27
审稿时长
>12 weeks
期刊介绍:
The journal provides a focus for the dissemination of new results about the elicitation, representation and validation of requirements of software intensive information systems or applications. Theoretical and applied submissions are welcome, but all papers must explicitly address:
-the practical consequences of the ideas for the design of complex systems
-how the ideas should be evaluated by the reflective practitioner
The journal is motivated by a multi-disciplinary view that considers requirements not only in terms of software components specification but also in terms of activities for their elicitation, representation and agreement, carried out within an organisational and social context. To this end, contributions are sought from fields such as software engineering, information systems, occupational sociology, cognitive and organisational psychology, human-computer interaction, computer-supported cooperative work, linguistics and philosophy for work addressing specifically requirements engineering issues.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


