{"title":"A temporal shift reconstruction network for compressive video sensing","authors":"Zhenfei Gu, Chao Zhou, Guofeng Lin","doi":"10.1049/cvi2.12234","DOIUrl":null,"url":null,"abstract":"<p>Compressive sensing provides a promising sampling paradigm for video acquisition for resource-limited sensor applications. However, the reconstruction of original video signals from sub-sampled measurements is still a great challenge. To exploit the temporal redundancies within videos during the recovery, previous works tend to perform alignment on initial reconstructions, which are too coarse to provide accurate motion estimations. To solve this problem, the authors propose a novel reconstruction network, named TSRN, for compressive video sensing. Specifically, the authors utilise a number of stacked temporal shift reconstruction blocks (TSRBs) to enhance the initial reconstruction progressively. Each TSRB could learn the temporal structures by exchanging information with last and next time step, and no additional computations is imposed on the network compared to regular 2D convolutions due to the high efficiency of temporal shift operations. After the enhancement, a bidirectional alignment module to build accurate temporal dependencies directly with the help of optical flows is employed. Different from previous methods that only extract supplementary information from the key frames, the proposed alignment module can receive temporal information from the whole video sequence via bidirectional propagations, thus yielding better performance. Experimental results verify the superiority of the proposed method over other state-of-the-art approaches quantitatively and qualitatively.</p>","PeriodicalId":56304,"journal":{"name":"IET Computer Vision","volume":"18 4","pages":"448-457"},"PeriodicalIF":1.5000,"publicationDate":"2023-09-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1049/cvi2.12234","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"IET Computer Vision","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1049/cvi2.12234","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
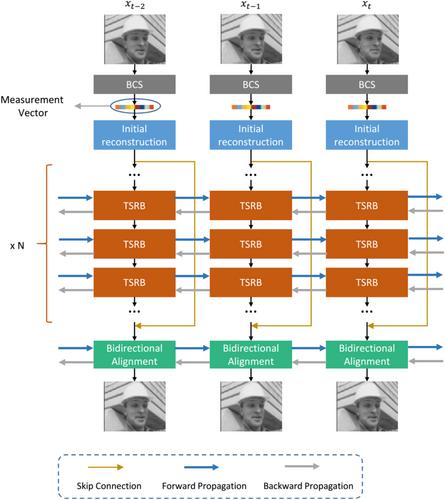
Compressive sensing provides a promising sampling paradigm for video acquisition for resource-limited sensor applications. However, the reconstruction of original video signals from sub-sampled measurements is still a great challenge. To exploit the temporal redundancies within videos during the recovery, previous works tend to perform alignment on initial reconstructions, which are too coarse to provide accurate motion estimations. To solve this problem, the authors propose a novel reconstruction network, named TSRN, for compressive video sensing. Specifically, the authors utilise a number of stacked temporal shift reconstruction blocks (TSRBs) to enhance the initial reconstruction progressively. Each TSRB could learn the temporal structures by exchanging information with last and next time step, and no additional computations is imposed on the network compared to regular 2D convolutions due to the high efficiency of temporal shift operations. After the enhancement, a bidirectional alignment module to build accurate temporal dependencies directly with the help of optical flows is employed. Different from previous methods that only extract supplementary information from the key frames, the proposed alignment module can receive temporal information from the whole video sequence via bidirectional propagations, thus yielding better performance. Experimental results verify the superiority of the proposed method over other state-of-the-art approaches quantitatively and qualitatively.
期刊介绍:
IET Computer Vision seeks original research papers in a wide range of areas of computer vision. The vision of the journal is to publish the highest quality research work that is relevant and topical to the field, but not forgetting those works that aim to introduce new horizons and set the agenda for future avenues of research in computer vision.
IET Computer Vision welcomes submissions on the following topics:
Biologically and perceptually motivated approaches to low level vision (feature detection, etc.);
Perceptual grouping and organisation
Representation, analysis and matching of 2D and 3D shape
Shape-from-X
Object recognition
Image understanding
Learning with visual inputs
Motion analysis and object tracking
Multiview scene analysis
Cognitive approaches in low, mid and high level vision
Control in visual systems
Colour, reflectance and light
Statistical and probabilistic models
Face and gesture
Surveillance
Biometrics and security
Robotics
Vehicle guidance
Automatic model aquisition
Medical image analysis and understanding
Aerial scene analysis and remote sensing
Deep learning models in computer vision
Both methodological and applications orientated papers are welcome.
Manuscripts submitted are expected to include a detailed and analytical review of the literature and state-of-the-art exposition of the original proposed research and its methodology, its thorough experimental evaluation, and last but not least, comparative evaluation against relevant and state-of-the-art methods. Submissions not abiding by these minimum requirements may be returned to authors without being sent to review.
Special Issues Current Call for Papers:
Computer Vision for Smart Cameras and Camera Networks - https://digital-library.theiet.org/files/IET_CVI_SC.pdf
Computer Vision for the Creative Industries - https://digital-library.theiet.org/files/IET_CVI_CVCI.pdf

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


