Efficient continuous kNN join over dynamic high-dimensional data
IF 3.4
3区 计算机科学
Q2 COMPUTER SCIENCE, INFORMATION SYSTEMS
World Wide Web-Internet and Web Information Systems
Pub Date : 2023-09-11
DOI:10.1007/s11280-023-01204-9
引用次数: 0
Abstract
Abstract Given a user dataset $$\varvec{U}$$
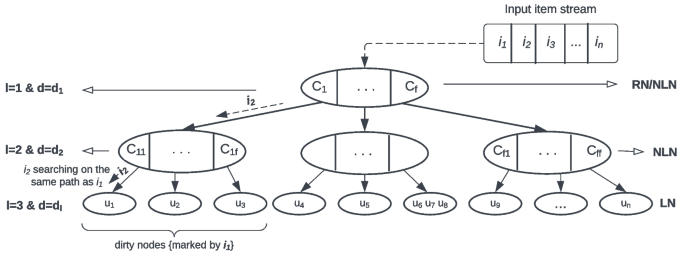
动态高维数据的高效连续kNN连接
给定一个用户数据集$$\varvec{U}$$ U和一个对象数据集$$\varvec{I}$$ I,高维空间的kNN连接查询从对象数据集$$\varvec{I}$$ I返回数据集$$\varvec{U}$$ U中每个对象的$$\varvec{k}$$ k个最近邻居。kNN连接是许多应用程序中基本且必要的操作,例如数据库、数据挖掘、计算机视觉、多媒体、机器学习、推荐系统等等。在现实世界中,随着对象的添加或删除,数据集经常动态更新。本文提出了动态高维数据上连续kNN连接的新方法。我们首先提出HDR $$^+$$ + Tree,它支持更高效的插入、删除和批量更新。进一步观察到现有方法依赖于全球相关数据集来有效降维,我们提出了HDR森林。它对数据集进行聚类,并构建多个HDR树来捕获数据之间的局部相关性。因此,我们的HDR森林能够有效地处理非全局相关的数据集。提出了两种新的优化方法,包括数据项PCA状态的预计算和数据项删除时基于修剪的kNN重新计算。为了工作的完整性,我们还提出了HDR树中PCA降维计算距离的证明。在真实数据集上的大量实验表明,所提出的方法和优化优于朴素RkNN连接和HDR树的基线算法。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

World Wide Web-Internet and Web Information Systems
工程技术-计算机:软件工程
CiteScore
7.30
自引率
10.80%
发文量
131
审稿时长
6 months
期刊介绍:
World Wide Web: Internet and Web Information Systems (WWW) is an international, archival, peer-reviewed journal which covers all aspects of the World Wide Web, including issues related to architectures, applications, Internet and Web information systems, and communities. The purpose of this journal is to provide an international forum for researchers, professionals, and industrial practitioners to share their rapidly developing knowledge and report on new advances in Internet and web-based systems. The journal also focuses on all database- and information-system topics that relate to the Internet and the Web, particularly on ways to model, design, develop, integrate, and manage these systems.
Appearing quarterly, the journal publishes (1) papers describing original ideas and new results, (2) vision papers, (3) reviews of important techniques in related areas, (4) innovative application papers, and (5) progress reports on major international research projects. Papers published in the WWW journal deal with subjects directly or indirectly related to the World Wide Web. The WWW journal provides timely, in-depth coverage of the most recent developments in the World Wide Web discipline to enable anyone involved to keep up-to-date with this dynamically changing technology.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


