Financial Causality Extraction Based on Universal Dependencies and Clue Expressions
IF 2
4区 计算机科学
Q3 COMPUTER SCIENCE, HARDWARE & ARCHITECTURE
引用次数: 0
Abstract
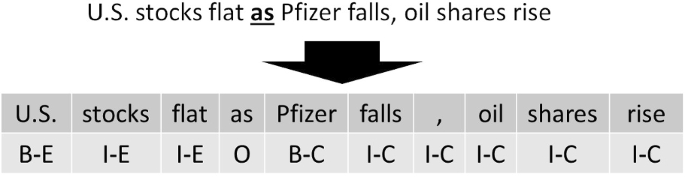
Abstract This paper proposes a method to extract financial causal knowledge from bi-lingual text data. Domain-specific causal knowledge plays an important role in human intellectual activities, especially expert decision making. Especially, in the financial area, fund managers, financial analysts, etc. need causal knowledge for their works. Natural language processing is highly effective for extracting human-perceived causality; however, there are two major problems with existing methods. First, causality relative to global activities must be extracted from text data in multiple languages; however, multilingual causality extraction has not been established to date. Second, technologies to extract complex causal structures, e.g., nested causalities, are insufficient. We consider that a model using universal dependencies can extract bi-lingual and nested causalities can be established using clues, e.g., “because” and “since.” Thus, to solve these problems, the proposed model extracts nested causalities based on such clues and universal dependencies in multilingual text data. The proposed financial causality extraction method was evaluated on bi-lingual text data from the financial domain, and the results demonstrated that the proposed model outperformed existing models in the experiment.
基于普遍依赖和线索表达的金融因果关系提取
摘要提出了一种从双语文本数据中提取金融因果知识的方法。特定领域的因果知识在人类智力活动,特别是专家决策中起着重要的作用。特别是在金融领域,基金经理、金融分析师等都需要因果知识。自然语言处理在提取人类感知的因果关系方面非常有效;然而,现有方法存在两个主要问题。首先,必须从多种语言的文本数据中提取与全球活动相关的因果关系;然而,迄今为止,多语言因果关系提取尚未建立。其次,提取复杂因果结构(如嵌套因果关系)的技术不足。我们认为使用通用依赖关系的模型可以提取双语,并且可以使用线索(例如,“because”和“since”)建立嵌套因果关系。因此,为了解决这些问题,该模型基于这些线索和多语言文本数据中的普遍依赖关系提取嵌套因果关系。在金融领域的双语文本数据上对所提出的金融因果关系提取方法进行了评估,结果表明所提出的模型在实验中优于现有模型。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

New Generation Computing
工程技术-计算机:理论方法
CiteScore
5.90
自引率
15.40%
发文量
47
审稿时长
>12 weeks
期刊介绍:
The journal is specially intended to support the development of new computational and cognitive paradigms stemming from the cross-fertilization of various research fields. These fields include, but are not limited to, programming (logic, constraint, functional, object-oriented), distributed/parallel computing, knowledge-based systems, agent-oriented systems, and cognitive aspects of human embodied knowledge. It also encourages theoretical and/or practical papers concerning all types of learning, knowledge discovery, evolutionary mechanisms, human cognition and learning, and emergent systems that can lead to key technologies enabling us to build more complex and intelligent systems. The editorial board hopes that New Generation Computing will work as a catalyst among active researchers with broad interests by ensuring a smooth publication process.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


