{"title":"ChatGPT-based biological and psychological data imputation","authors":"Anam Nazir, Muhammad Nadeem Cheeema, Ze Wang","doi":"10.1016/j.metrad.2023.100034","DOIUrl":null,"url":null,"abstract":"<div><p>Missing data are a common problem for large cohort or longitudinal research and have been handled through data imputation. Based on simplified models such as linear or nonlinear interpolations, current imputation methods may not be accurate for real-life data such as biological and behavioral data. The purpose of this work was to explore the capability of ChatGPT, a powerful Large Language Model (LLM) developed by OpenAI, for biological and psychological data imputation. We tested the feasibility using data from the Human Connectome Project. Performance was evaluated by comparing the imputed data against known ground truth (GT) and measured with metrics like Pearson correlation coefficient (r), relative accuracy (MP), and mean absolute error (MAE). Comparative analyses with traditional imputation techniques are also conducted to demonstrate the superior efficacy of the ChatGPT as a data imputer. In summary, through customized data-to-text prompting engineering, ChatGPT can successfully capture intricate patterns and dependencies within biological data, resulting in precise imputations. Fine-tuning ChatGPT with domain-specific biological vocabulary with human in-loop as an interpreter enhances the accuracy and relevance of the imputations.</p></div>","PeriodicalId":100921,"journal":{"name":"Meta-Radiology","volume":"1 3","pages":"Article 100034"},"PeriodicalIF":0.0000,"publicationDate":"2023-11-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S2950162823000346/pdfft?md5=acce895c3937994b83ab89acba27ca65&pid=1-s2.0-S2950162823000346-main.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Meta-Radiology","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2950162823000346","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
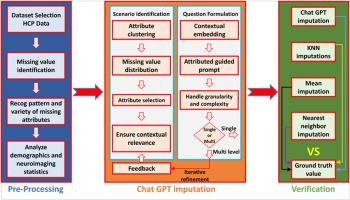
Missing data are a common problem for large cohort or longitudinal research and have been handled through data imputation. Based on simplified models such as linear or nonlinear interpolations, current imputation methods may not be accurate for real-life data such as biological and behavioral data. The purpose of this work was to explore the capability of ChatGPT, a powerful Large Language Model (LLM) developed by OpenAI, for biological and psychological data imputation. We tested the feasibility using data from the Human Connectome Project. Performance was evaluated by comparing the imputed data against known ground truth (GT) and measured with metrics like Pearson correlation coefficient (r), relative accuracy (MP), and mean absolute error (MAE). Comparative analyses with traditional imputation techniques are also conducted to demonstrate the superior efficacy of the ChatGPT as a data imputer. In summary, through customized data-to-text prompting engineering, ChatGPT can successfully capture intricate patterns and dependencies within biological data, resulting in precise imputations. Fine-tuning ChatGPT with domain-specific biological vocabulary with human in-loop as an interpreter enhances the accuracy and relevance of the imputations.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


