Enhancing cluster analysis via topological manifold learning
IF 2.8
3区 计算机科学
Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
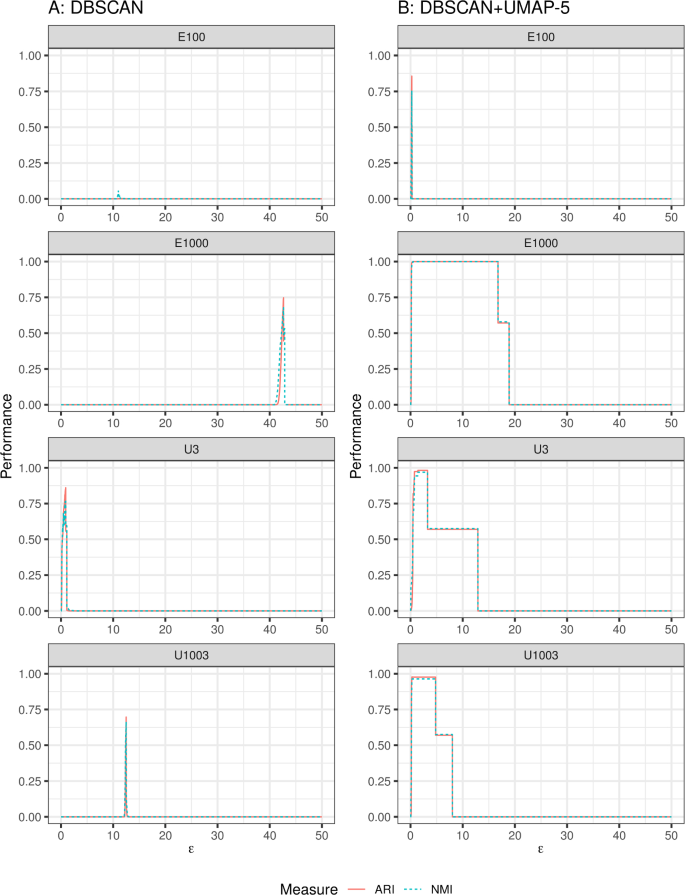
Abstract We discuss topological aspects of cluster analysis and show that inferring the topological structure of a dataset before clustering it can considerably enhance cluster detection: we show that clustering embedding vectors representing the inherent structure of a dataset instead of the observed feature vectors themselves is highly beneficial. To demonstrate, we combine manifold learning method UMAP for inferring the topological structure with density-based clustering method DBSCAN. Synthetic and real data results show that this both simplifies and improves clustering in a diverse set of low- and high-dimensional problems including clusters of varying density and/or entangled shapes. Our approach simplifies clustering because topological pre-processing consistently reduces parameter sensitivity of DBSCAN. Clustering the resulting embeddings with DBSCAN can then even outperform complex methods such as SPECTACL and ClusterGAN. Finally, our investigation suggests that the crucial issue in clustering does not appear to be the nominal dimension of the data or how many irrelevant features it contains, but rather how separable the clusters are in the ambient observation space they are embedded in, which is usually the (high-dimensional) Euclidean space defined by the features of the data. The approach is successful because it performs the cluster analysis after projecting the data into a more suitable space that is optimized for separability, in some sense.
通过拓扑流形学习增强聚类分析
我们讨论了聚类分析的拓扑方面,并表明在聚类之前推断数据集的拓扑结构可以大大增强聚类检测:我们表明聚类嵌入向量表示数据集的固有结构而不是观察到的特征向量本身是非常有益的。为了证明这一点,我们将用于推断拓扑结构的流形学习方法UMAP与基于密度的聚类方法DBSCAN相结合。综合数据和实际数据结果表明,这种方法既简化了聚类,也改善了各种低维和高维问题的聚类,包括密度变化和/或纠缠形状的聚类。我们的方法简化了聚类,因为拓扑预处理始终降低了DBSCAN的参数敏感性。然后用DBSCAN对结果嵌入进行聚类,甚至可以胜过复杂的方法,如SPECTACL和ClusterGAN。最后,我们的研究表明,聚类的关键问题似乎不是数据的标称维度或它包含多少不相关的特征,而是聚类在它们嵌入的环境观测空间中如何可分离,这通常是由数据特征定义的(高维)欧几里德空间。该方法是成功的,因为它在将数据投影到更合适的空间后执行聚类分析,该空间在某种意义上针对可分离性进行了优化。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Data Mining and Knowledge Discovery
工程技术-计算机:人工智能
CiteScore
10.40
自引率
4.20%
发文量
68
审稿时长
10 months
期刊介绍:
Advances in data gathering, storage, and distribution have created a need for computational tools and techniques to aid in data analysis. Data Mining and Knowledge Discovery in Databases (KDD) is a rapidly growing area of research and application that builds on techniques and theories from many fields, including statistics, databases, pattern recognition and learning, data visualization, uncertainty modelling, data warehousing and OLAP, optimization, and high performance computing.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


