Han Lyu , Zhixiang Wang , Jia Li , Jing Sun , Xinghao Wang , Pengling Ren , Linkun Cai , Zhenchang Wang , Max Wintermark
{"title":"Generative pretrained transformer 4: an innovative approach to facilitate value-based healthcare","authors":"Han Lyu , Zhixiang Wang , Jia Li , Jing Sun , Xinghao Wang , Pengling Ren , Linkun Cai , Zhenchang Wang , Max Wintermark","doi":"10.1016/j.imed.2023.09.001","DOIUrl":null,"url":null,"abstract":"<div><h3>Objective</h3><p>Appropriate medical imaging is important for value-based care. We aim to evaluate the performance of generative pretrained transformer 4 (GPT-4), an innovative natural language processing model, providing appropriate medical imaging automatically in different clinical scenarios.</p></div><div><h3>Methods</h3><p>Institutional Review Boards (IRB) approval was not required due to the use of nonidentifiable data. Instead, we used 112 questions from the American College of Radiology (ACR) Radiology-TEACHES Program as prompts, which is an open-sourced question and answer program to guide appropriate medical imaging. We included 69 free-text case vignettes and 43 simplified cases. For the performance evaluation of GPT-4 and GPT-3.5, we considered the recommendations of ACR guidelines as the gold standard, and then three radiologists analyzed the consistency of the responses from the GPT models with those of the ACR. We set a five-score criterion for the evaluation of the consistency. A paired t-test was applied to assess the statistical significance of the findings.</p></div><div><h3>Results</h3><p>For the performance of the GPT models in free-text case vignettes, the accuracy of GPT-4 was 92.9%, whereas the accuracy of GPT-3.5 was just 78.3%. GPT-4 can provide more appropriate suggestions to reduce the overutilization of medical imaging than GPT-3.5 (<em>t</em> = 3.429, <em>P</em> = 0.001). For the performance of the GPT models in simplified scenarios, the accuracy of GPT-4 and GPT-3.5 was 66.5% and 60.0%, respectively. The differences were not statistically significant (<em>t</em> = 1.858, <em>P</em> = 0.070). GPT-4 was characterized by longer reaction times (27.1 s in average) and extensive responses (137.1 words on average) than GPT-3.5.</p></div><div><h3>Conclusion</h3><p>As an advanced tool for improving value-based healthcare in clinics, GPT-4 may guide appropriate medical imaging accurately and efficiently.</p></div>","PeriodicalId":73400,"journal":{"name":"Intelligent medicine","volume":"4 1","pages":"Pages 10-15"},"PeriodicalIF":4.4000,"publicationDate":"2024-02-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S2667102623000608/pdfft?md5=cecccaadb9c5cc3a9e585509d068faea&pid=1-s2.0-S2667102623000608-main.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Intelligent medicine","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2667102623000608","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
Abstract
Objective
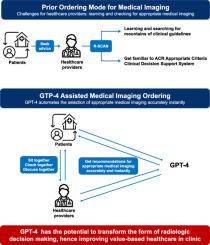
Appropriate medical imaging is important for value-based care. We aim to evaluate the performance of generative pretrained transformer 4 (GPT-4), an innovative natural language processing model, providing appropriate medical imaging automatically in different clinical scenarios.
Methods
Institutional Review Boards (IRB) approval was not required due to the use of nonidentifiable data. Instead, we used 112 questions from the American College of Radiology (ACR) Radiology-TEACHES Program as prompts, which is an open-sourced question and answer program to guide appropriate medical imaging. We included 69 free-text case vignettes and 43 simplified cases. For the performance evaluation of GPT-4 and GPT-3.5, we considered the recommendations of ACR guidelines as the gold standard, and then three radiologists analyzed the consistency of the responses from the GPT models with those of the ACR. We set a five-score criterion for the evaluation of the consistency. A paired t-test was applied to assess the statistical significance of the findings.
Results
For the performance of the GPT models in free-text case vignettes, the accuracy of GPT-4 was 92.9%, whereas the accuracy of GPT-3.5 was just 78.3%. GPT-4 can provide more appropriate suggestions to reduce the overutilization of medical imaging than GPT-3.5 (t = 3.429, P = 0.001). For the performance of the GPT models in simplified scenarios, the accuracy of GPT-4 and GPT-3.5 was 66.5% and 60.0%, respectively. The differences were not statistically significant (t = 1.858, P = 0.070). GPT-4 was characterized by longer reaction times (27.1 s in average) and extensive responses (137.1 words on average) than GPT-3.5.
Conclusion
As an advanced tool for improving value-based healthcare in clinics, GPT-4 may guide appropriate medical imaging accurately and efficiently.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


