Detecting Tweets Containing Cannabidiol-Related COVID-19 Misinformation Using Transformer Language Models and Warning Letters From Food and Drug Administration: Content Analysis and Identification.
Jason Turner, Mehmed Kantardzic, Rachel Vickers-Smith, Andrew G Brown
{"title":"Detecting Tweets Containing Cannabidiol-Related COVID-19 Misinformation Using Transformer Language Models and Warning Letters From Food and Drug Administration: Content Analysis and Identification.","authors":"Jason Turner, Mehmed Kantardzic, Rachel Vickers-Smith, Andrew G Brown","doi":"10.2196/38390","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>COVID-19 has introduced yet another opportunity to web-based sellers of loosely regulated substances, such as cannabidiol (CBD), to promote sales under false pretenses of curing the disease. Therefore, it has become necessary to innovate ways to identify such instances of misinformation.</p><p><strong>Objective: </strong>We sought to identify COVID-19 misinformation as it relates to the sales or promotion of CBD and used transformer-based language models to identify tweets semantically similar to quotes taken from known instances of misinformation. In this case, the known misinformation was the publicly available Warning Letters from Food and Drug Administration (FDA).</p><p><strong>Methods: </strong>We collected tweets using CBD- and COVID-19-related terms. Using a previously trained model, we extracted the tweets indicating commercialization and sales of CBD and annotated those containing COVID-19 misinformation according to the FDA definitions. We encoded the collection of tweets and misinformation quotes into sentence vectors and then calculated the cosine similarity between each quote and each tweet. This allowed us to establish a threshold to identify tweets that were making false claims regarding CBD and COVID-19 while minimizing the instances of false positives.</p><p><strong>Results: </strong>We demonstrated that by using quotes taken from Warning Letters issued by FDA to perpetrators of similar misinformation, we can identify semantically similar tweets that also contain misinformation. This was accomplished by identifying a cosine distance threshold between the sentence vectors of the Warning Letters and tweets.</p><p><strong>Conclusions: </strong>This research shows that commercial CBD or COVID-19 misinformation can potentially be identified and curbed using transformer-based language models and known prior instances of misinformation. Our approach functions without the need for labeled data, potentially reducing the time at which misinformation can be identified. Our approach shows promise in that it is easily adapted to identify other forms of misinformation related to loosely regulated substances.</p>","PeriodicalId":73554,"journal":{"name":"JMIR infodemiology","volume":"3 ","pages":"e38390"},"PeriodicalIF":2.3000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9941900/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR infodemiology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/38390","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
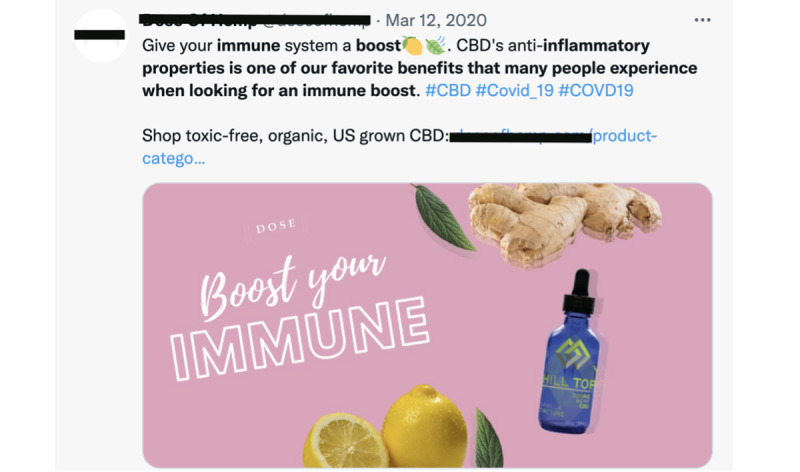
Background: COVID-19 has introduced yet another opportunity to web-based sellers of loosely regulated substances, such as cannabidiol (CBD), to promote sales under false pretenses of curing the disease. Therefore, it has become necessary to innovate ways to identify such instances of misinformation.
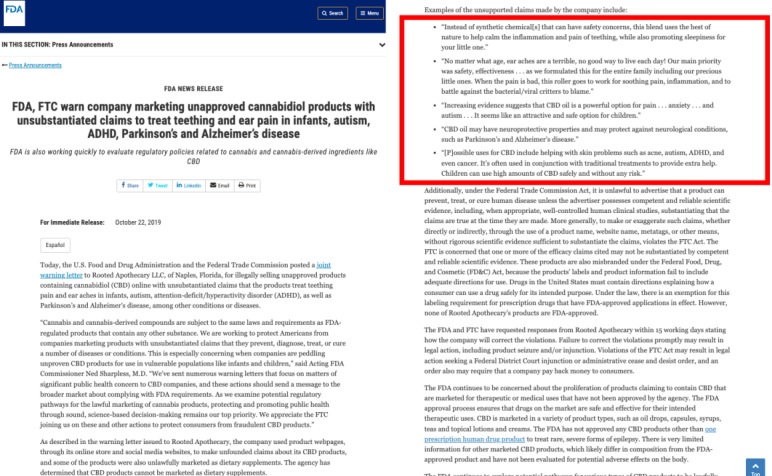
Objective: We sought to identify COVID-19 misinformation as it relates to the sales or promotion of CBD and used transformer-based language models to identify tweets semantically similar to quotes taken from known instances of misinformation. In this case, the known misinformation was the publicly available Warning Letters from Food and Drug Administration (FDA).
Methods: We collected tweets using CBD- and COVID-19-related terms. Using a previously trained model, we extracted the tweets indicating commercialization and sales of CBD and annotated those containing COVID-19 misinformation according to the FDA definitions. We encoded the collection of tweets and misinformation quotes into sentence vectors and then calculated the cosine similarity between each quote and each tweet. This allowed us to establish a threshold to identify tweets that were making false claims regarding CBD and COVID-19 while minimizing the instances of false positives.
Results: We demonstrated that by using quotes taken from Warning Letters issued by FDA to perpetrators of similar misinformation, we can identify semantically similar tweets that also contain misinformation. This was accomplished by identifying a cosine distance threshold between the sentence vectors of the Warning Letters and tweets.
Conclusions: This research shows that commercial CBD or COVID-19 misinformation can potentially be identified and curbed using transformer-based language models and known prior instances of misinformation. Our approach functions without the need for labeled data, potentially reducing the time at which misinformation can be identified. Our approach shows promise in that it is easily adapted to identify other forms of misinformation related to loosely regulated substances.
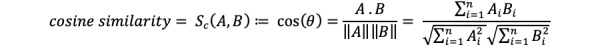

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


