{"title":"Towards automatic text-based estimation of depression through symptom prediction.","authors":"Kirill Milintsevich, Kairit Sirts, Gaël Dias","doi":"10.1186/s40708-023-00185-9","DOIUrl":null,"url":null,"abstract":"<p><p>Major Depressive Disorder (MDD) is one of the most common and comorbid mental disorders that impacts a person's day-to-day activity. In addition, MDD affects one's linguistic footprint, which is reflected by subtle changes in speech production. This allows us to use natural language processing (NLP) techniques to build a neural classifier to detect depression from speech transcripts. Typically, current NLP systems discriminate only between the depressed and non-depressed states. This approach, however, disregards the complexity of the clinical picture of depression, as different people with MDD can suffer from different sets of depression symptoms. Therefore, predicting individual symptoms can provide more fine-grained information about a person's condition. In this work, we look at the depression classification problem through the prism of the symptom network analysis approach, which shifts attention from a categorical analysis of depression towards a personalized analysis of symptom profiles. For that purpose, we trained a multi-target hierarchical regression model to predict individual depression symptoms from patient-psychiatrist interview transcripts from the DAIC-WOZ corpus. Our model achieved results on par with state-of-the-art models on both binary diagnostic classification and depression severity prediction while at the same time providing a more fine-grained overview of individual symptoms for each person. The model achieved a mean absolute error (MAE) from 0.438 to 0.830 on eight depression symptoms and showed state-of-the-art results in binary depression estimation (73.9 macro-F1) and total depression score prediction (3.78 MAE). Moreover, the model produced a symptom correlation graph that is structurally identical to the real one. The proposed symptom-based approach provides more in-depth information about the depressive condition by focusing on the individual symptoms rather than a general binary diagnosis.</p>","PeriodicalId":37465,"journal":{"name":"Brain Informatics","volume":"10 1","pages":"4"},"PeriodicalIF":4.5000,"publicationDate":"2023-02-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9925661/pdf/","citationCount":"1","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Brain Informatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/s40708-023-00185-9","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"Computer Science","Score":null,"Total":0}
引用次数: 1
Abstract
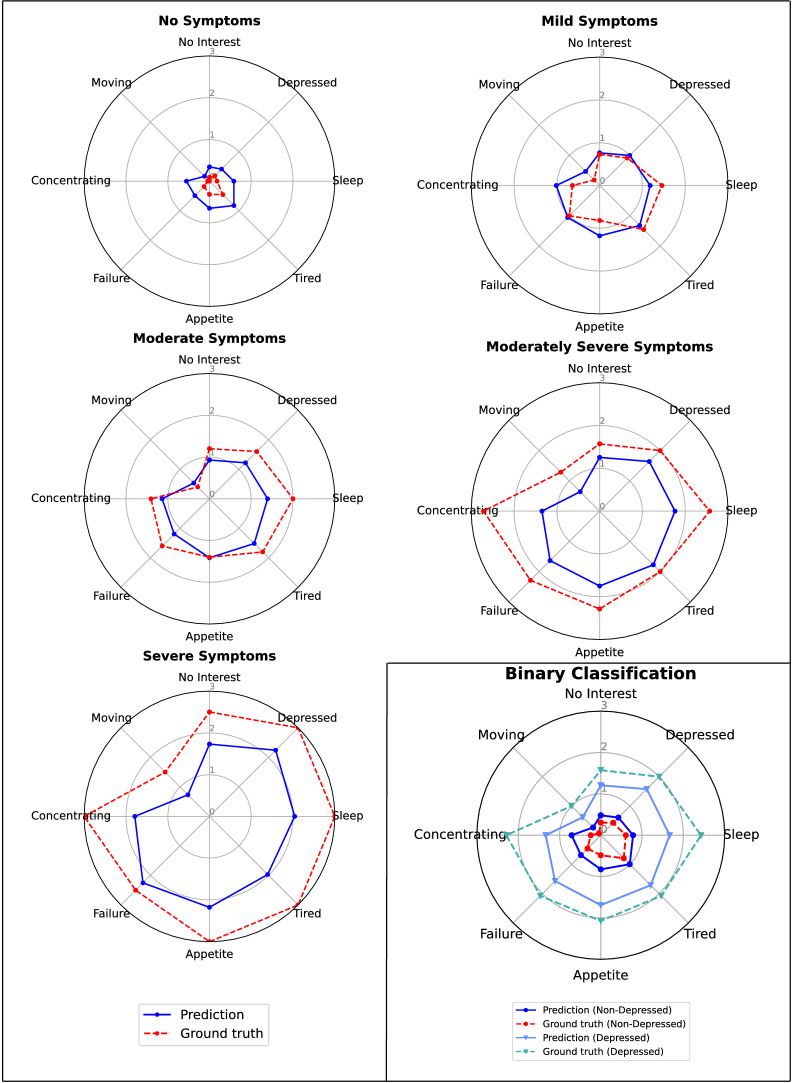
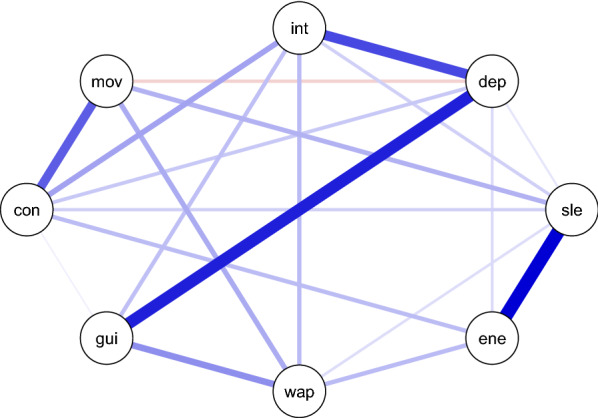
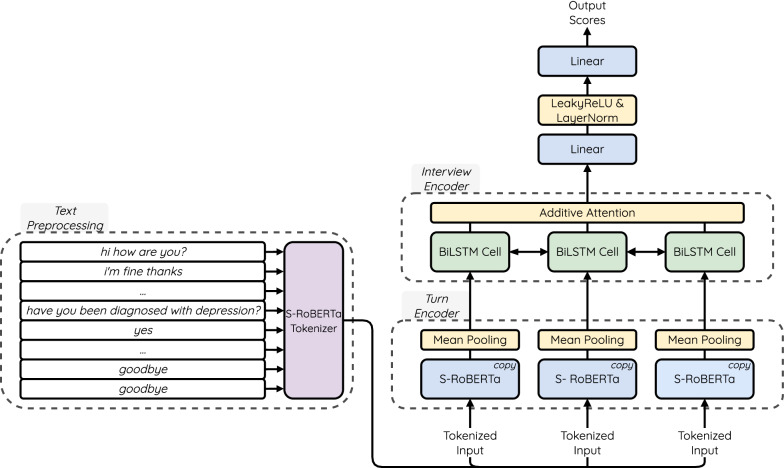
Major Depressive Disorder (MDD) is one of the most common and comorbid mental disorders that impacts a person's day-to-day activity. In addition, MDD affects one's linguistic footprint, which is reflected by subtle changes in speech production. This allows us to use natural language processing (NLP) techniques to build a neural classifier to detect depression from speech transcripts. Typically, current NLP systems discriminate only between the depressed and non-depressed states. This approach, however, disregards the complexity of the clinical picture of depression, as different people with MDD can suffer from different sets of depression symptoms. Therefore, predicting individual symptoms can provide more fine-grained information about a person's condition. In this work, we look at the depression classification problem through the prism of the symptom network analysis approach, which shifts attention from a categorical analysis of depression towards a personalized analysis of symptom profiles. For that purpose, we trained a multi-target hierarchical regression model to predict individual depression symptoms from patient-psychiatrist interview transcripts from the DAIC-WOZ corpus. Our model achieved results on par with state-of-the-art models on both binary diagnostic classification and depression severity prediction while at the same time providing a more fine-grained overview of individual symptoms for each person. The model achieved a mean absolute error (MAE) from 0.438 to 0.830 on eight depression symptoms and showed state-of-the-art results in binary depression estimation (73.9 macro-F1) and total depression score prediction (3.78 MAE). Moreover, the model produced a symptom correlation graph that is structurally identical to the real one. The proposed symptom-based approach provides more in-depth information about the depressive condition by focusing on the individual symptoms rather than a general binary diagnosis.
期刊介绍:
Brain Informatics is an international, peer-reviewed, interdisciplinary open-access journal published under the brand SpringerOpen, which provides a unique platform for researchers and practitioners to disseminate original research on computational and informatics technologies related to brain. This journal addresses the computational, cognitive, physiological, biological, physical, ecological and social perspectives of brain informatics. It also welcomes emerging information technologies and advanced neuro-imaging technologies, such as big data analytics and interactive knowledge discovery related to various large-scale brain studies and their applications. This journal will publish high-quality original research papers, brief reports and critical reviews in all theoretical, technological, clinical and interdisciplinary studies that make up the field of brain informatics and its applications in brain-machine intelligence, brain-inspired intelligent systems, mental health and brain disorders, etc. The scope of papers includes the following five tracks: Track 1: Cognitive and Computational Foundations of Brain Science Track 2: Human Information Processing Systems Track 3: Brain Big Data Analytics, Curation and Management Track 4: Informatics Paradigms for Brain and Mental Health Research Track 5: Brain-Machine Intelligence and Brain-Inspired Computing

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


