Marcello Nesca, Alan Katz, Carson K Leung, Lisa M Lix
{"title":"A scoping review of preprocessing methods for unstructured text data to assess data quality.","authors":"Marcello Nesca, Alan Katz, Carson K Leung, Lisa M Lix","doi":"10.23889/ijpds.v6i1.1757","DOIUrl":null,"url":null,"abstract":"<p><strong>Introduction: </strong>Unstructured text data (UTD) are increasingly found in many databases that were never intended to be used for research, including electronic medical record (EMR) databases. Data quality can impact the usefulness of UTD for research. UTD are typically prepared for analysis (i.e., preprocessed) and analyzed using natural language processing (NLP) techniques. Different NLP methods are used to preprocess UTD and may affect data quality.</p><p><strong>Objective: </strong>Our objective was to systematically document current research and practices about NLP preprocessing methods to describe or improve the quality of UTD, including UTD found in EMR databases.</p><p><strong>Methods: </strong>A scoping review was undertaken of peer-reviewed studies published between December 2002 and January 2021. Scopus, Web of Science, ProQuest, and EBSCOhost were searched for literature relevant to the study objective. Information extracted from the studies included article characteristics (i.e., year of publication, journal discipline), data characteristics, types of preprocessing methods, and data quality topics. Study data were presented using a narrative synthesis.</p><p><strong>Results: </strong>A total of 41 articles were included in the scoping review; over 50% were published between 2016 and 2021. Almost 20% of the articles were published in health science journals. Common preprocessing methods included removal of extraneous text elements such as stop words, punctuation, and numbers, word tokenization, and parts of speech tagging. Data quality topics for articles about EMR data included misspelled words, security (i.e., de-identification), word variability, sources of noise, quality of annotations, and ambiguity of abbreviations.</p><p><strong>Conclusions: </strong>Multiple NLP techniques have been proposed to preprocess UTD, with some differences in techniques applied to EMR data. There are similarities in the data quality dimensions used to characterize structured data and UTD. While a few general-purpose measures of data quality that do not require external data; most of these focus on the measurement of noise.</p>","PeriodicalId":36483,"journal":{"name":"International Journal of Population Data Science","volume":"7 1","pages":"1757"},"PeriodicalIF":2.2000,"publicationDate":"2022-10-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/a2/2f/ijpds-07-1757.PMC10476151.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Population Data Science","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.23889/ijpds.v6i1.1757","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/1/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
Introduction: Unstructured text data (UTD) are increasingly found in many databases that were never intended to be used for research, including electronic medical record (EMR) databases. Data quality can impact the usefulness of UTD for research. UTD are typically prepared for analysis (i.e., preprocessed) and analyzed using natural language processing (NLP) techniques. Different NLP methods are used to preprocess UTD and may affect data quality.
Objective: Our objective was to systematically document current research and practices about NLP preprocessing methods to describe or improve the quality of UTD, including UTD found in EMR databases.
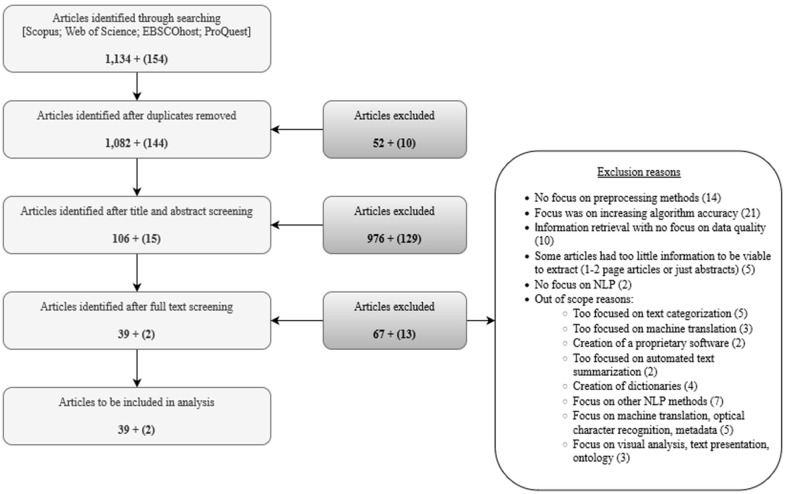
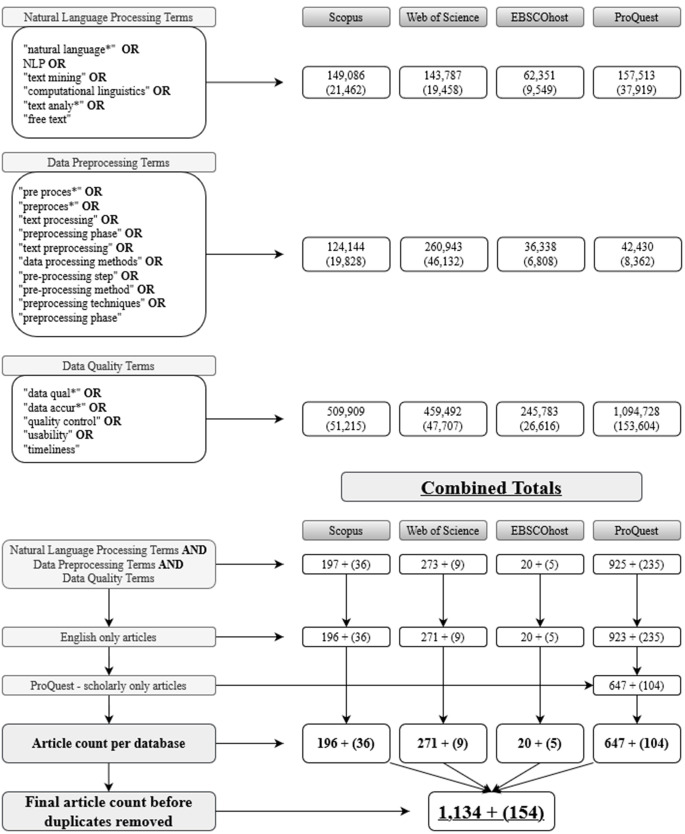
Methods: A scoping review was undertaken of peer-reviewed studies published between December 2002 and January 2021. Scopus, Web of Science, ProQuest, and EBSCOhost were searched for literature relevant to the study objective. Information extracted from the studies included article characteristics (i.e., year of publication, journal discipline), data characteristics, types of preprocessing methods, and data quality topics. Study data were presented using a narrative synthesis.
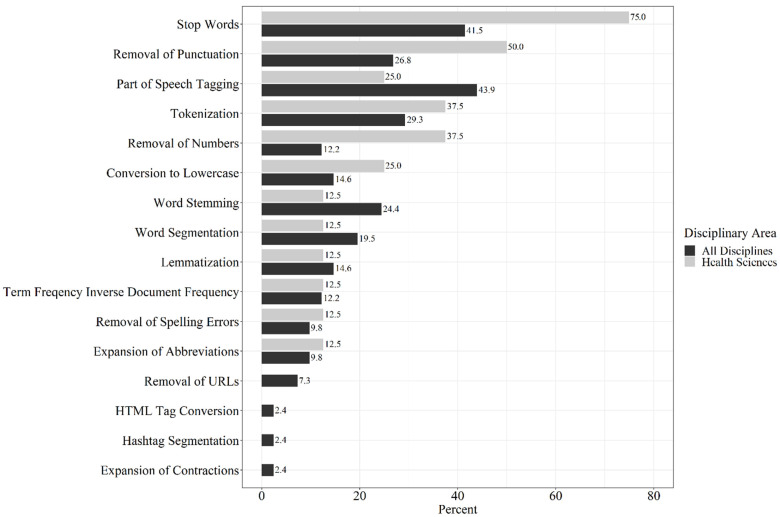
Results: A total of 41 articles were included in the scoping review; over 50% were published between 2016 and 2021. Almost 20% of the articles were published in health science journals. Common preprocessing methods included removal of extraneous text elements such as stop words, punctuation, and numbers, word tokenization, and parts of speech tagging. Data quality topics for articles about EMR data included misspelled words, security (i.e., de-identification), word variability, sources of noise, quality of annotations, and ambiguity of abbreviations.
Conclusions: Multiple NLP techniques have been proposed to preprocess UTD, with some differences in techniques applied to EMR data. There are similarities in the data quality dimensions used to characterize structured data and UTD. While a few general-purpose measures of data quality that do not require external data; most of these focus on the measurement of noise.
简介:非结构化文本数据(UTD)越来越多地出现在许多数据库中,这些数据库从未打算用于研究,包括电子病历(EMR)数据库。数据质量会影响UTD对研究的有用性。UTD通常准备用于分析(即预处理),并使用自然语言处理(NLP)技术进行分析。使用不同的NLP方法对UTD进行预处理,可能会影响数据质量。目的:我们的目标是系统地记录当前关于NLP预处理方法的研究和实践,以描述或提高UTD的质量,包括EMR数据库中发现的UTD。方法:对2002年12月至2021年1月间发表的同行评议研究进行范围综述。检索Scopus、Web of Science、ProQuest和EBSCOhost,查找与研究目标相关的文献。从研究中提取的信息包括文章特征(即出版年份、期刊学科)、数据特征、预处理方法类型和数据质量主题。研究数据采用叙事综合的方式呈现。结果:共纳入41篇文献;超过50%的论文发表于2016年至2021年之间。近20%的文章发表在卫生科学期刊上。常见的预处理方法包括删除无关的文本元素,如停止词、标点符号和数字、单词标记和词性标记。关于EMR数据的文章的数据质量主题包括拼写错误的单词、安全性(即去标识化)、单词可变性、噪声源、注释质量和缩写的模糊性。结论:已经提出了多种NLP技术来预处理UTD,但应用于EMR数据的技术存在一些差异。用于描述结构化数据和UTD的数据质量维度有相似之处。虽然有一些不需要外部数据的通用数据质量度量;其中大多数集中在噪声的测量上。

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


