Zhivko Zhelev, Jaime Peters, Morwenna Rogers, Michael Allen, Goda Kijauskaite, Farah Seedat, Elizabeth Wilkinson, Christopher Hyde
{"title":"Test accuracy of artificial intelligence-based grading of fundus images in diabetic retinopathy screening: A systematic review.","authors":"Zhivko Zhelev, Jaime Peters, Morwenna Rogers, Michael Allen, Goda Kijauskaite, Farah Seedat, Elizabeth Wilkinson, Christopher Hyde","doi":"10.1177/09691413221144382","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>To systematically review the accuracy of artificial intelligence (AI)-based systems for grading of fundus images in diabetic retinopathy (DR) screening.</p><p><strong>Methods: </strong>We searched MEDLINE, EMBASE, the Cochrane Library and the ClinicalTrials.gov from 1st January 2000 to 27th August 2021. Accuracy studies published in English were included if they met the pre-specified inclusion criteria. Selection of studies for inclusion, data extraction and quality assessment were conducted by one author with a second reviewer independently screening and checking 20% of titles. Results were analysed narratively.</p><p><strong>Results: </strong>Forty-three studies evaluating 15 deep learning (DL) and 4 machine learning (ML) systems were included. Nine systems were evaluated in a single study each. Most studies were judged to be at high or unclear risk of bias in at least one QUADAS-2 domain. Sensitivity for referable DR and higher grades was ≥85% while specificity varied and was <80% for all ML systems and in 6/31 studies evaluating DL systems. Studies reported high accuracy for detection of ungradable images, but the latter were analysed and reported inconsistently. Seven studies reported that AI was more sensitive but less specific than human graders.</p><p><strong>Conclusions: </strong>AI-based systems are more sensitive than human graders and could be safe to use in clinical practice but have variable specificity. However, for many systems evidence is limited, at high risk of bias and may not generalise across settings. Therefore, pre-implementation assessment in the target clinical pathway is essential to obtain reliable and applicable accuracy estimates.</p>","PeriodicalId":51089,"journal":{"name":"Journal of Medical Screening","volume":"30 3","pages":"97-112"},"PeriodicalIF":2.3000,"publicationDate":"2023-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10399100/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Medical Screening","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1177/09691413221144382","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/1/9 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"PUBLIC, ENVIRONMENTAL & OCCUPATIONAL HEALTH","Score":null,"Total":0}
引用次数: 0
Abstract
Objectives: To systematically review the accuracy of artificial intelligence (AI)-based systems for grading of fundus images in diabetic retinopathy (DR) screening.
Methods: We searched MEDLINE, EMBASE, the Cochrane Library and the ClinicalTrials.gov from 1st January 2000 to 27th August 2021. Accuracy studies published in English were included if they met the pre-specified inclusion criteria. Selection of studies for inclusion, data extraction and quality assessment were conducted by one author with a second reviewer independently screening and checking 20% of titles. Results were analysed narratively.
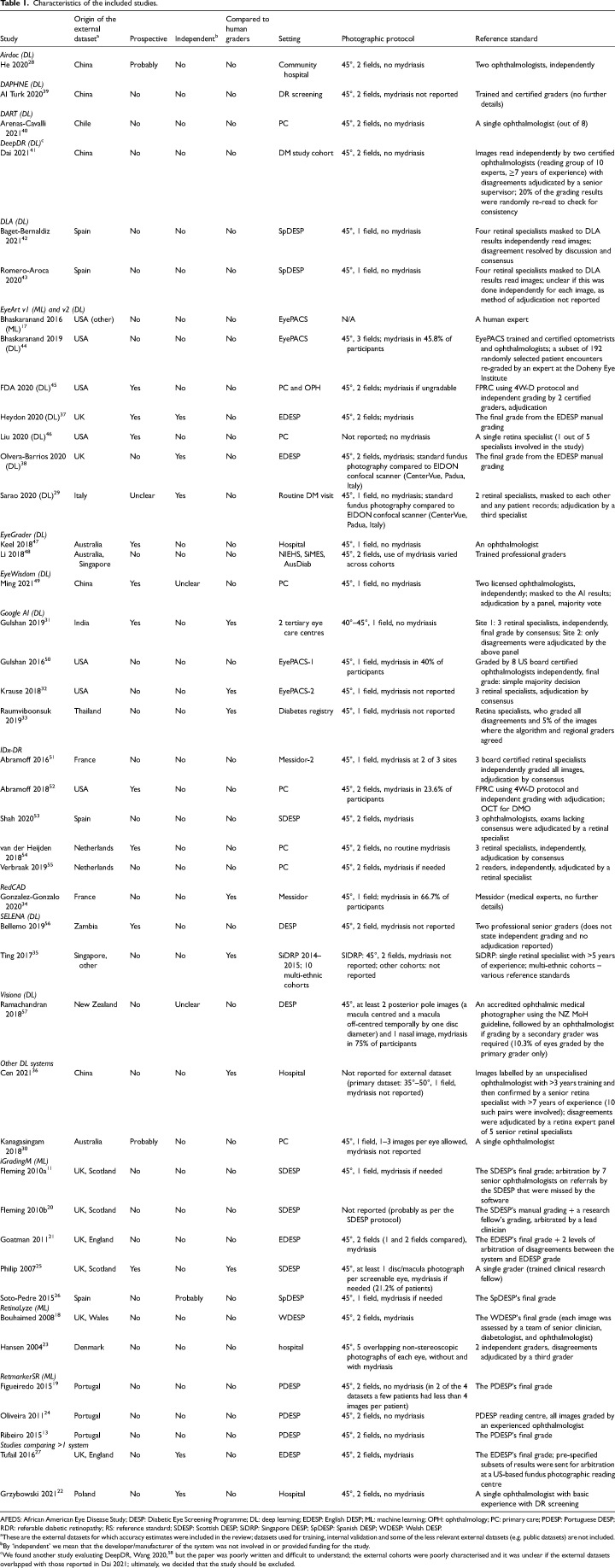
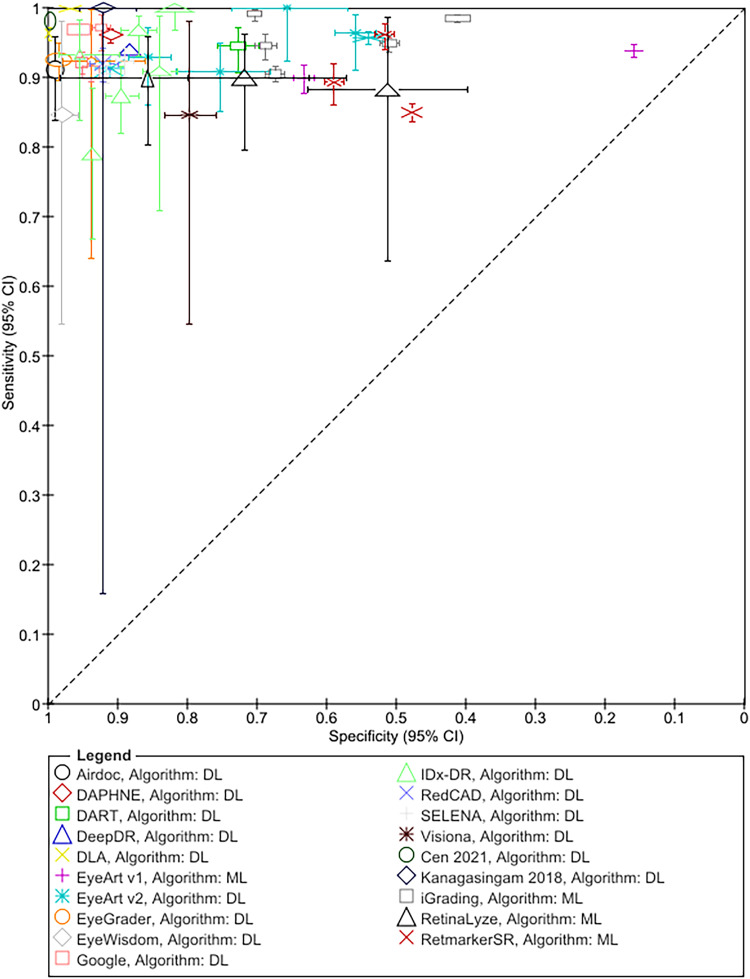
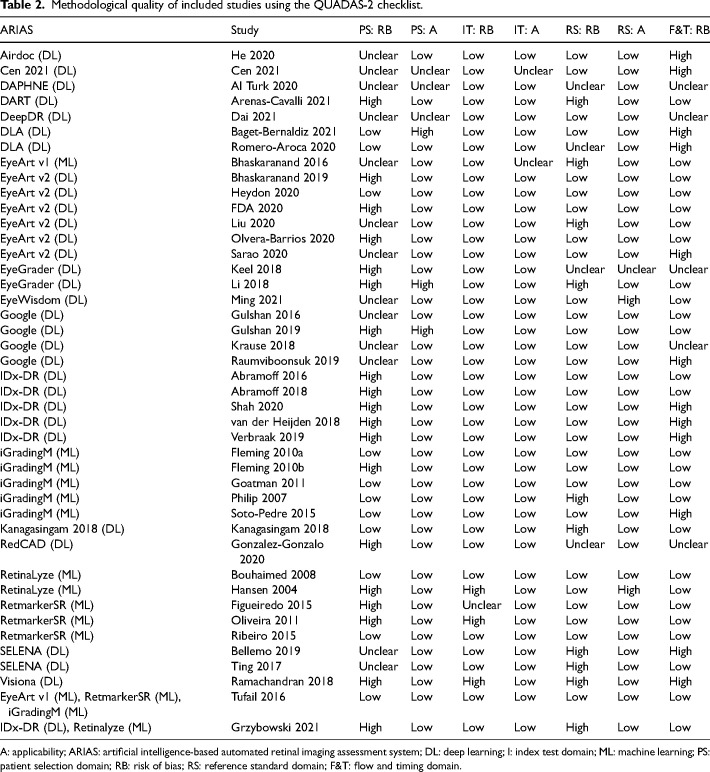
Results: Forty-three studies evaluating 15 deep learning (DL) and 4 machine learning (ML) systems were included. Nine systems were evaluated in a single study each. Most studies were judged to be at high or unclear risk of bias in at least one QUADAS-2 domain. Sensitivity for referable DR and higher grades was ≥85% while specificity varied and was <80% for all ML systems and in 6/31 studies evaluating DL systems. Studies reported high accuracy for detection of ungradable images, but the latter were analysed and reported inconsistently. Seven studies reported that AI was more sensitive but less specific than human graders.
Conclusions: AI-based systems are more sensitive than human graders and could be safe to use in clinical practice but have variable specificity. However, for many systems evidence is limited, at high risk of bias and may not generalise across settings. Therefore, pre-implementation assessment in the target clinical pathway is essential to obtain reliable and applicable accuracy estimates.
期刊介绍:
Journal of Medical Screening, a fully peer reviewed journal, is concerned with all aspects of medical screening, particularly the publication of research that advances screening theory and practice. The journal aims to increase awareness of the principles of screening (quantitative and statistical aspects), screening techniques and procedures and methodologies from all specialties. An essential subscription for physicians, clinicians and academics with an interest in screening, epidemiology and public health.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


