{"title":"μ- PBWT: a lightweight r-indexing of the PBWT for storing and querying UK Biobank data.","authors":"Davide Cozzi, Massimiliano Rossi, Simone Rubinacci, Travis Gagie, Dominik Köppl, Christina Boucher, Paola Bonizzoni","doi":"10.1093/bioinformatics/btad552","DOIUrl":null,"url":null,"abstract":"<p><strong>Motivation: </strong>The Positional Burrows-Wheeler Transform (PBWT) is a data structure that indexes haplotype sequences in a manner that enables finding maximal haplotype matches in h sequences containing w variation sites in O(hw) time. This represents a significant improvement over classical quadratic-time approaches. However, the original PBWT data structure does not allow for queries over Biobank panels that consist of several millions of haplotypes, if an index of the haplotypes must be kept entirely in memory.</p><p><strong>Results: </strong>In this article, we leverage the notion of r-index proposed for the BWT to present a memory-efficient method for constructing and storing the run-length encoded PBWT, and computing set maximal matches (SMEMs) queries in haplotype sequences. We implement our method, which we refer to as μ-PBWT, and evaluate it on datasets of 1000 Genome Project and UK Biobank data. Our experiments demonstrate that the μ-PBWT reduces the memory usage up to a factor of 20% compared to the best current PBWT-based indexing. In particular, μ-PBWT produces an index that stores high-coverage whole genome sequencing data of chromosome 20 in about a third of the space of its BCF file. μ-PBWT is an adaptation of techniques for the run-length compressed BWT for the PBWT (RLPBWT) and it is based on keeping in memory only a succinct representation of the RLPBWT that still allows the efficient computation of set maximal matches (SMEMs) over the original panel.</p><p><strong>Availability and implementation: </strong>Our implementation is open source and available at https://github.com/dlcgold/muPBWT. The binary is available at https://bioconda.github.io/recipes/mupbwt/README.html.</p>","PeriodicalId":8903,"journal":{"name":"Bioinformatics","volume":"39 9","pages":""},"PeriodicalIF":5.4000,"publicationDate":"2023-09-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10502237/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1093/bioinformatics/btad552","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
引用次数: 0
Abstract
Motivation: The Positional Burrows-Wheeler Transform (PBWT) is a data structure that indexes haplotype sequences in a manner that enables finding maximal haplotype matches in h sequences containing w variation sites in O(hw) time. This represents a significant improvement over classical quadratic-time approaches. However, the original PBWT data structure does not allow for queries over Biobank panels that consist of several millions of haplotypes, if an index of the haplotypes must be kept entirely in memory.
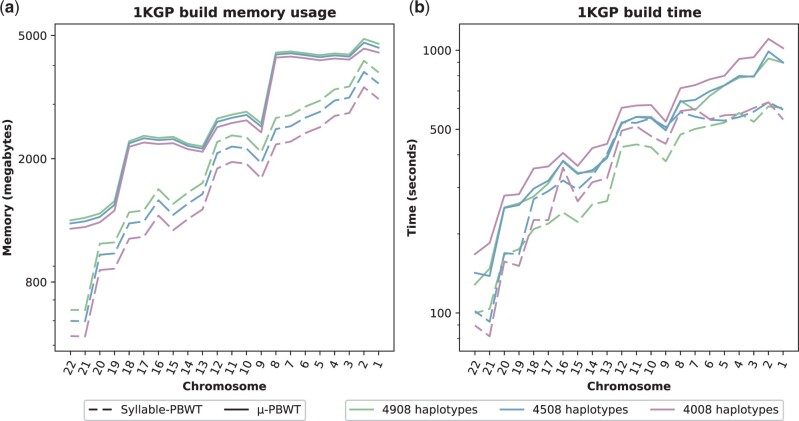
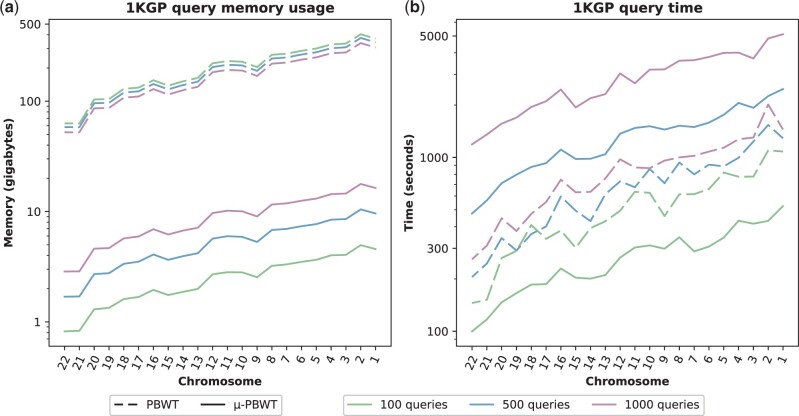
Results: In this article, we leverage the notion of r-index proposed for the BWT to present a memory-efficient method for constructing and storing the run-length encoded PBWT, and computing set maximal matches (SMEMs) queries in haplotype sequences. We implement our method, which we refer to as μ-PBWT, and evaluate it on datasets of 1000 Genome Project and UK Biobank data. Our experiments demonstrate that the μ-PBWT reduces the memory usage up to a factor of 20% compared to the best current PBWT-based indexing. In particular, μ-PBWT produces an index that stores high-coverage whole genome sequencing data of chromosome 20 in about a third of the space of its BCF file. μ-PBWT is an adaptation of techniques for the run-length compressed BWT for the PBWT (RLPBWT) and it is based on keeping in memory only a succinct representation of the RLPBWT that still allows the efficient computation of set maximal matches (SMEMs) over the original panel.
Availability and implementation: Our implementation is open source and available at https://github.com/dlcgold/muPBWT. The binary is available at https://bioconda.github.io/recipes/mupbwt/README.html.
期刊介绍:
The leading journal in its field, Bioinformatics publishes the highest quality scientific papers and review articles of interest to academic and industrial researchers. Its main focus is on new developments in genome bioinformatics and computational biology. Two distinct sections within the journal - Discovery Notes and Application Notes- focus on shorter papers; the former reporting biologically interesting discoveries using computational methods, the latter exploring the applications used for experiments.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


