Ziheng Duan, Yi Dai, Ahyeon Hwang, Cheyu Lee, Kaichi Xie, Chutong Xiao, Min Xu, Matthew J Girgenti, Jing Zhang
{"title":"iHerd: an integrative hierarchical graph representation learning framework to quantify network changes and prioritize risk genes in disease.","authors":"Ziheng Duan, Yi Dai, Ahyeon Hwang, Cheyu Lee, Kaichi Xie, Chutong Xiao, Min Xu, Matthew J Girgenti, Jing Zhang","doi":"10.1371/journal.pcbi.1011444","DOIUrl":null,"url":null,"abstract":"<p><p>Different genes form complex networks within cells to carry out critical cellular functions, while network alterations in this process can potentially introduce downstream transcriptome perturbations and phenotypic variations. Therefore, developing efficient and interpretable methods to quantify network changes and pinpoint driver genes across conditions is crucial. We propose a hierarchical graph representation learning method, called iHerd. Given a set of networks, iHerd first hierarchically generates a series of coarsened sub-graphs in a data-driven manner, representing network modules at different resolutions (e.g., the level of signaling pathways). Then, it sequentially learns low-dimensional node representations at all hierarchical levels via efficient graph embedding. Lastly, iHerd projects separate gene embeddings onto the same latent space in its graph alignment module to calculate a rewiring index for driver gene prioritization. To demonstrate its effectiveness, we applied iHerd on a tumor-to-normal GRN rewiring analysis and cell-type-specific GCN analysis using single-cell multiome data of the brain. We showed that iHerd can effectively pinpoint novel and well-known risk genes in different diseases. Distinct from existing models, iHerd's graph coarsening for hierarchical learning allows us to successfully classify network driver genes into early and late divergent genes (EDGs and LDGs), emphasizing genes with extensive network changes across and within signaling pathway levels. This unique approach for driver gene classification can provide us with deeper molecular insights. The code is freely available at https://github.com/aicb-ZhangLabs/iHerd. All other relevant data are within the manuscript and supporting information files.</p>","PeriodicalId":49688,"journal":{"name":"PLoS Computational Biology","volume":"19 9","pages":"e1011444"},"PeriodicalIF":4.3000,"publicationDate":"2023-09-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10513318/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"PLoS Computational Biology","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1371/journal.pcbi.1011444","RegionNum":2,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/9/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Different genes form complex networks within cells to carry out critical cellular functions, while network alterations in this process can potentially introduce downstream transcriptome perturbations and phenotypic variations. Therefore, developing efficient and interpretable methods to quantify network changes and pinpoint driver genes across conditions is crucial. We propose a hierarchical graph representation learning method, called iHerd. Given a set of networks, iHerd first hierarchically generates a series of coarsened sub-graphs in a data-driven manner, representing network modules at different resolutions (e.g., the level of signaling pathways). Then, it sequentially learns low-dimensional node representations at all hierarchical levels via efficient graph embedding. Lastly, iHerd projects separate gene embeddings onto the same latent space in its graph alignment module to calculate a rewiring index for driver gene prioritization. To demonstrate its effectiveness, we applied iHerd on a tumor-to-normal GRN rewiring analysis and cell-type-specific GCN analysis using single-cell multiome data of the brain. We showed that iHerd can effectively pinpoint novel and well-known risk genes in different diseases. Distinct from existing models, iHerd's graph coarsening for hierarchical learning allows us to successfully classify network driver genes into early and late divergent genes (EDGs and LDGs), emphasizing genes with extensive network changes across and within signaling pathway levels. This unique approach for driver gene classification can provide us with deeper molecular insights. The code is freely available at https://github.com/aicb-ZhangLabs/iHerd. All other relevant data are within the manuscript and supporting information files.
期刊介绍:
PLOS Computational Biology features works of exceptional significance that further our understanding of living systems at all scales—from molecules and cells, to patient populations and ecosystems—through the application of computational methods. Readers include life and computational scientists, who can take the important findings presented here to the next level of discovery.
Research articles must be declared as belonging to a relevant section. More information about the sections can be found in the submission guidelines.
Research articles should model aspects of biological systems, demonstrate both methodological and scientific novelty, and provide profound new biological insights.
Generally, reliability and significance of biological discovery through computation should be validated and enriched by experimental studies. Inclusion of experimental validation is not required for publication, but should be referenced where possible. Inclusion of experimental validation of a modest biological discovery through computation does not render a manuscript suitable for PLOS Computational Biology.
Research articles specifically designated as Methods papers should describe outstanding methods of exceptional importance that have been shown, or have the promise to provide new biological insights. The method must already be widely adopted, or have the promise of wide adoption by a broad community of users. Enhancements to existing published methods will only be considered if those enhancements bring exceptional new capabilities.
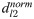
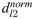
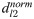

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


