Karen Guerrero-Vázquez, Gabriel Del Rio, Carlos A Brizuela
{"title":"Cell-penetrating peptides predictors: A comparative analysis of methods and datasets.","authors":"Karen Guerrero-Vázquez, Gabriel Del Rio, Carlos A Brizuela","doi":"10.1002/minf.202300104","DOIUrl":null,"url":null,"abstract":"<p><p>Cell-Penetrating Peptides (CPP) are emerging as an alternative to small-molecule drugs to expand the range of biomolecules that can be targeted for therapeutic purposes. Due to the importance of identifying and designing new CPP, a great variety of predictors have been developed to achieve these goals. To establish a ranking for these predictors, a couple of recent studies compared their performances on specific datasets, yet their conclusions cannot determine if the ranking obtained is due to the model, the set of descriptors or the datasets used to test the predictors. We present a systematic study of the influence of the peptide sequence's similarity of the datasets on the predictors' performance. The analysis reveals that the datasets used for training have a stronger influence on the predictors performance than the model or descriptors employed. We show that datasets with low sequence similarity between the positive and negative examples can be easily separated, and the tested classifiers showed good performance on them. On the other hand, a dataset with high sequence similarity between CPP and non-CPP will be a hard dataset, and it should be the one to be used for assessing the performance of new predictors.</p>","PeriodicalId":18853,"journal":{"name":"Molecular Informatics","volume":" ","pages":"e202300104"},"PeriodicalIF":2.8000,"publicationDate":"2023-11-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Molecular Informatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1002/minf.202300104","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/9/6 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"CHEMISTRY, MEDICINAL","Score":null,"Total":0}
引用次数: 0
Abstract
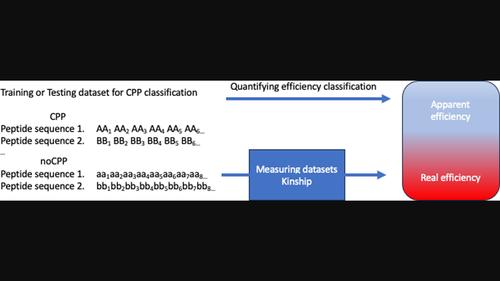
Cell-Penetrating Peptides (CPP) are emerging as an alternative to small-molecule drugs to expand the range of biomolecules that can be targeted for therapeutic purposes. Due to the importance of identifying and designing new CPP, a great variety of predictors have been developed to achieve these goals. To establish a ranking for these predictors, a couple of recent studies compared their performances on specific datasets, yet their conclusions cannot determine if the ranking obtained is due to the model, the set of descriptors or the datasets used to test the predictors. We present a systematic study of the influence of the peptide sequence's similarity of the datasets on the predictors' performance. The analysis reveals that the datasets used for training have a stronger influence on the predictors performance than the model or descriptors employed. We show that datasets with low sequence similarity between the positive and negative examples can be easily separated, and the tested classifiers showed good performance on them. On the other hand, a dataset with high sequence similarity between CPP and non-CPP will be a hard dataset, and it should be the one to be used for assessing the performance of new predictors.
期刊介绍:
Molecular Informatics is a peer-reviewed, international forum for publication of high-quality, interdisciplinary research on all molecular aspects of bio/cheminformatics and computer-assisted molecular design. Molecular Informatics succeeded QSAR & Combinatorial Science in 2010.
Molecular Informatics presents methodological innovations that will lead to a deeper understanding of ligand-receptor interactions, macromolecular complexes, molecular networks, design concepts and processes that demonstrate how ideas and design concepts lead to molecules with a desired structure or function, preferably including experimental validation.
The journal''s scope includes but is not limited to the fields of drug discovery and chemical biology, protein and nucleic acid engineering and design, the design of nanomolecular structures, strategies for modeling of macromolecular assemblies, molecular networks and systems, pharmaco- and chemogenomics, computer-assisted screening strategies, as well as novel technologies for the de novo design of biologically active molecules. As a unique feature Molecular Informatics publishes so-called "Methods Corner" review-type articles which feature important technological concepts and advances within the scope of the journal.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


