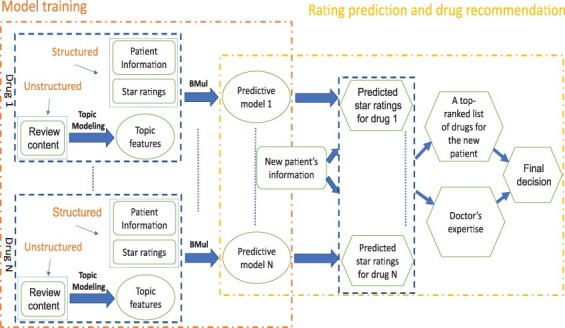
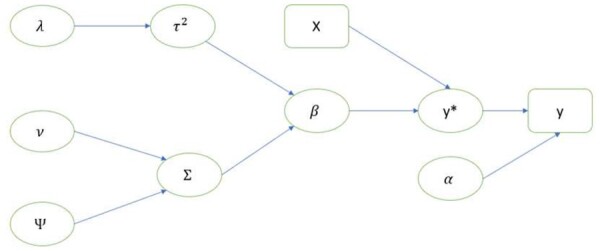
{"title":"Bayesian multitask learning for medicine recommendation based on online patient reviews.","authors":"Yichen Cheng, Yusen Xia, Xinlei Wang","doi":"10.1093/bioinformatics/btad491","DOIUrl":null,"url":null,"abstract":"<p><strong>Motivation: </strong>We propose a drug recommendation model that integrates information from both structured data (patient demographic information) and unstructured texts (patient reviews). It is based on multitask learning to predict review ratings of several satisfaction-related measures for a given medicine, where related tasks can learn from each other for prediction. The learned models can then be applied to new patients for drug recommendation. This is fundamentally different from most recommender systems in e-commerce, which do not work well for new customers (referred to as the cold-start problem). To extract information from review texts, we employ both topic modeling and sentiment analysis. We further incorporate variable selection into the model via Bayesian LASSO, which aims to filter out irrelevant features. To our best knowledge, this is the first Bayesian multitask learning method for ordinal responses. We are also the first to apply multitask learning to medicine recommendation. The sample code and data are made available at GitHub: https://github.com/thrushcyc-github/BMull.</p><p><strong>Results: </strong>We evaluate the proposed method on two sets of drug reviews involving 17 depression/high blood pressure-related drugs. Overall, our method performs better than existing benchmark methods in terms of accuracy and AUC (area under the receiver operating characteristic curve). It is effective even with a small sample size and only a few available features, and more robust to possible noninformative covariates. Due to our model explainability, insights generated from our model may work as a useful reference for doctors. In practice, however, a final decision should be carefully made by combining the information from the proposed recommender with doctors' domain knowledge and past experience.</p><p><strong>Availability and implementation: </strong>The sample code and data are publicly available at GitHub: https://github.com/thrushcyc-github/BMull.</p>","PeriodicalId":8903,"journal":{"name":"Bioinformatics","volume":"39 8","pages":""},"PeriodicalIF":5.4000,"publicationDate":"2023-08-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10425196/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1093/bioinformatics/btad491","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
引用次数: 0
Abstract
Motivation: We propose a drug recommendation model that integrates information from both structured data (patient demographic information) and unstructured texts (patient reviews). It is based on multitask learning to predict review ratings of several satisfaction-related measures for a given medicine, where related tasks can learn from each other for prediction. The learned models can then be applied to new patients for drug recommendation. This is fundamentally different from most recommender systems in e-commerce, which do not work well for new customers (referred to as the cold-start problem). To extract information from review texts, we employ both topic modeling and sentiment analysis. We further incorporate variable selection into the model via Bayesian LASSO, which aims to filter out irrelevant features. To our best knowledge, this is the first Bayesian multitask learning method for ordinal responses. We are also the first to apply multitask learning to medicine recommendation. The sample code and data are made available at GitHub: https://github.com/thrushcyc-github/BMull.
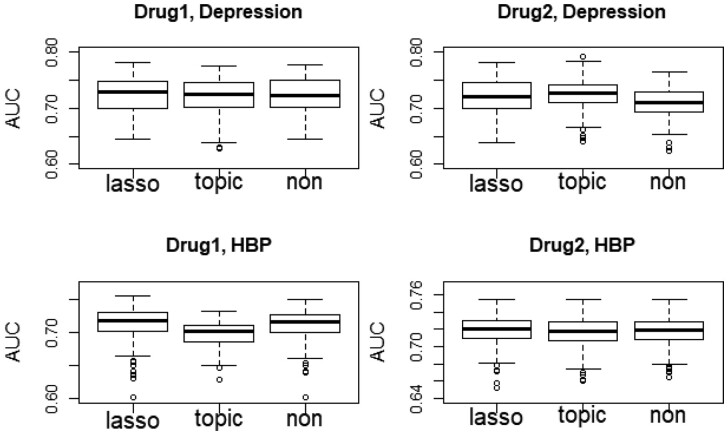
Results: We evaluate the proposed method on two sets of drug reviews involving 17 depression/high blood pressure-related drugs. Overall, our method performs better than existing benchmark methods in terms of accuracy and AUC (area under the receiver operating characteristic curve). It is effective even with a small sample size and only a few available features, and more robust to possible noninformative covariates. Due to our model explainability, insights generated from our model may work as a useful reference for doctors. In practice, however, a final decision should be carefully made by combining the information from the proposed recommender with doctors' domain knowledge and past experience.
Availability and implementation: The sample code and data are publicly available at GitHub: https://github.com/thrushcyc-github/BMull.
期刊介绍:
The leading journal in its field, Bioinformatics publishes the highest quality scientific papers and review articles of interest to academic and industrial researchers. Its main focus is on new developments in genome bioinformatics and computational biology. Two distinct sections within the journal - Discovery Notes and Application Notes- focus on shorter papers; the former reporting biologically interesting discoveries using computational methods, the latter exploring the applications used for experiments.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


