反向稳定扩散:生成这张图片时使用了什么提示?
IF 4.3
3区 计算机科学
Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
摘要
文本到图像的扩散模型最近引起了许多研究人员的兴趣,而反转扩散过程对于更好地理解生成过程以及如何设计提示以获得所需的图像具有重要作用。为此,我们研究了在生成扩散模型生成图像的情况下预测提示嵌入的任务。我们考虑了一系列白盒模型和黑盒模型(可访问和不可访问扩散网络的权重)来处理所提出的任务。我们提出了一个新颖的学习框架,其中包括一个联合提示回归和多标签词汇分类目标,可生成改进的提示。为了进一步改进我们的方法,我们采用了一种课程学习程序,以促进学习具有较低标签噪声(即更好地对齐)的图像-提示对。我们在 DiffusionDB 数据集上进行了实验,从稳定扩散法生成的图像中预测文本提示。此外,我们还发现了一个有趣的现象:当模型直接用于文本到图像的生成时,在提示生成任务上训练扩散模型可以使模型生成的图像与输入提示更好地对齐。我们的代码可在 https://github.com/CroitoruAlin/Reverse-Stable-Diffusion 上公开下载。本文章由计算机程序翻译,如有差异,请以英文原文为准。
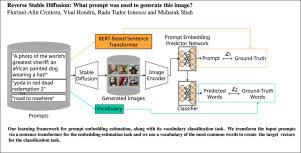
Reverse Stable Diffusion: What prompt was used to generate this image?
Text-to-image diffusion models have recently attracted the interest of many researchers, and inverting the diffusion process can play an important role in better understanding the generative process and how to engineer prompts in order to obtain the desired images. To this end, we study the task of predicting the prompt embedding given an image generated by a generative diffusion model. We consider a series of white-box and black-box models (with and without access to the weights of the diffusion network) to deal with the proposed task. We propose a novel learning framework comprising a joint prompt regression and multi-label vocabulary classification objective that generates improved prompts. To further improve our method, we employ a curriculum learning procedure that promotes the learning of image-prompt pairs with lower labeling noise (i.e. that are better aligned). We conduct experiments on the DiffusionDB data set, predicting text prompts from images generated by Stable Diffusion. In addition, we make an interesting discovery: training a diffusion model on the prompt generation task can make the model generate images that are much better aligned with the input prompts, when the model is directly reused for text-to-image generation. Our code is publicly available for download at https://github.com/CroitoruAlin/Reverse-Stable-Diffusion.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Computer Vision and Image Understanding
工程技术-工程:电子与电气
CiteScore
7.80
自引率
4.40%
发文量
112
审稿时长
79 days
期刊介绍:
The central focus of this journal is the computer analysis of pictorial information. Computer Vision and Image Understanding publishes papers covering all aspects of image analysis from the low-level, iconic processes of early vision to the high-level, symbolic processes of recognition and interpretation. A wide range of topics in the image understanding area is covered, including papers offering insights that differ from predominant views.
Research Areas Include:
• Theory
• Early vision
• Data structures and representations
• Shape
• Range
• Motion
• Matching and recognition
• Architecture and languages
• Vision systems
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


