Esther L. Meerwijk , Duncan C. McElfresh , Susana Martins , Suzanne R. Tamang
{"title":"在医疗资源有限的情况下,评估临床决策支持算法的准确性和公平性。","authors":"Esther L. Meerwijk , Duncan C. McElfresh , Susana Martins , Suzanne R. Tamang","doi":"10.1016/j.jbi.2024.104664","DOIUrl":null,"url":null,"abstract":"<div><h3>Objective</h3><p>Guidance on how to evaluate accuracy and algorithmic fairness across subgroups is missing for clinical models that flag patients for an intervention but when health care resources to administer that intervention are limited. We aimed to propose a framework of metrics that would fit this specific use case.</p></div><div><h3>Methods</h3><p>We evaluated the following metrics and applied them to a Veterans Health Administration clinical model that flags patients for intervention who are at risk of overdose or a suicidal event among outpatients who were prescribed opioids (N = 405,817): Receiver – Operating Characteristic and area under the curve, precision – recall curve, calibration – reliability curve, false positive rate, false negative rate, and false omission rate. In addition, we developed a new approach to visualize false positives and false negatives that we named ‘per true positive bars.’ We demonstrate the utility of these metrics to our use case for three cohorts of patients at the highest risk (top 0.5 %, 1.0 %, and 5.0 %) by evaluating algorithmic fairness across the following age groups: <=30, 31–50, 51–65, and >65 years old.</p></div><div><h3>Results</h3><p>Metrics that allowed us to assess group differences more clearly were the false positive rate, false negative rate, false omission rate, and the new ‘per true positive bars’. Metrics with limited utility to our use case were the Receiver – Operating Characteristic and area under the curve, the calibration – reliability curve, and the precision – recall curve.</p></div><div><h3>Conclusion</h3><p>There is no “one size fits all” approach to model performance monitoring and bias analysis. Our work informs future researchers and clinicians who seek to evaluate accuracy and fairness of predictive models that identify patients to intervene on in the context of limited health care resources. In terms of ease of interpretation and utility for our use case, the new ‘per true positive bars’ may be the most intuitive to a range of stakeholders and facilitates choosing a threshold that allows weighing false positives against false negatives, which is especially important when predicting severe adverse events.</p></div>","PeriodicalId":15263,"journal":{"name":"Journal of Biomedical Informatics","volume":"156 ","pages":"Article 104664"},"PeriodicalIF":4.0000,"publicationDate":"2024-06-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Evaluating accuracy and fairness of clinical decision support algorithms when health care resources are limited\",\"authors\":\"Esther L. Meerwijk , Duncan C. McElfresh , Susana Martins , Suzanne R. Tamang\",\"doi\":\"10.1016/j.jbi.2024.104664\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><h3>Objective</h3><p>Guidance on how to evaluate accuracy and algorithmic fairness across subgroups is missing for clinical models that flag patients for an intervention but when health care resources to administer that intervention are limited. We aimed to propose a framework of metrics that would fit this specific use case.</p></div><div><h3>Methods</h3><p>We evaluated the following metrics and applied them to a Veterans Health Administration clinical model that flags patients for intervention who are at risk of overdose or a suicidal event among outpatients who were prescribed opioids (N = 405,817): Receiver – Operating Characteristic and area under the curve, precision – recall curve, calibration – reliability curve, false positive rate, false negative rate, and false omission rate. In addition, we developed a new approach to visualize false positives and false negatives that we named ‘per true positive bars.’ We demonstrate the utility of these metrics to our use case for three cohorts of patients at the highest risk (top 0.5 %, 1.0 %, and 5.0 %) by evaluating algorithmic fairness across the following age groups: <=30, 31–50, 51–65, and >65 years old.</p></div><div><h3>Results</h3><p>Metrics that allowed us to assess group differences more clearly were the false positive rate, false negative rate, false omission rate, and the new ‘per true positive bars’. Metrics with limited utility to our use case were the Receiver – Operating Characteristic and area under the curve, the calibration – reliability curve, and the precision – recall curve.</p></div><div><h3>Conclusion</h3><p>There is no “one size fits all” approach to model performance monitoring and bias analysis. Our work informs future researchers and clinicians who seek to evaluate accuracy and fairness of predictive models that identify patients to intervene on in the context of limited health care resources. In terms of ease of interpretation and utility for our use case, the new ‘per true positive bars’ may be the most intuitive to a range of stakeholders and facilitates choosing a threshold that allows weighing false positives against false negatives, which is especially important when predicting severe adverse events.</p></div>\",\"PeriodicalId\":15263,\"journal\":{\"name\":\"Journal of Biomedical Informatics\",\"volume\":\"156 \",\"pages\":\"Article 104664\"},\"PeriodicalIF\":4.0000,\"publicationDate\":\"2024-06-06\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Biomedical Informatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S1532046424000820\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Informatics","FirstCategoryId":"3","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1532046424000820","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
Evaluating accuracy and fairness of clinical decision support algorithms when health care resources are limited
Objective
Guidance on how to evaluate accuracy and algorithmic fairness across subgroups is missing for clinical models that flag patients for an intervention but when health care resources to administer that intervention are limited. We aimed to propose a framework of metrics that would fit this specific use case.
Methods
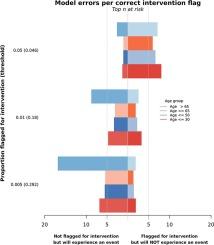
We evaluated the following metrics and applied them to a Veterans Health Administration clinical model that flags patients for intervention who are at risk of overdose or a suicidal event among outpatients who were prescribed opioids (N = 405,817): Receiver – Operating Characteristic and area under the curve, precision – recall curve, calibration – reliability curve, false positive rate, false negative rate, and false omission rate. In addition, we developed a new approach to visualize false positives and false negatives that we named ‘per true positive bars.’ We demonstrate the utility of these metrics to our use case for three cohorts of patients at the highest risk (top 0.5 %, 1.0 %, and 5.0 %) by evaluating algorithmic fairness across the following age groups: <=30, 31–50, 51–65, and >65 years old.
Results
Metrics that allowed us to assess group differences more clearly were the false positive rate, false negative rate, false omission rate, and the new ‘per true positive bars’. Metrics with limited utility to our use case were the Receiver – Operating Characteristic and area under the curve, the calibration – reliability curve, and the precision – recall curve.
Conclusion
There is no “one size fits all” approach to model performance monitoring and bias analysis. Our work informs future researchers and clinicians who seek to evaluate accuracy and fairness of predictive models that identify patients to intervene on in the context of limited health care resources. In terms of ease of interpretation and utility for our use case, the new ‘per true positive bars’ may be the most intuitive to a range of stakeholders and facilitates choosing a threshold that allows weighing false positives against false negatives, which is especially important when predicting severe adverse events.
期刊介绍:
The Journal of Biomedical Informatics reflects a commitment to high-quality original research papers, reviews, and commentaries in the area of biomedical informatics methodology. Although we publish articles motivated by applications in the biomedical sciences (for example, clinical medicine, health care, population health, and translational bioinformatics), the journal emphasizes reports of new methodologies and techniques that have general applicability and that form the basis for the evolving science of biomedical informatics. Articles on medical devices; evaluations of implemented systems (including clinical trials of information technologies); or papers that provide insight into a biological process, a specific disease, or treatment options would generally be more suitable for publication in other venues. Papers on applications of signal processing and image analysis are often more suitable for biomedical engineering journals or other informatics journals, although we do publish papers that emphasize the information management and knowledge representation/modeling issues that arise in the storage and use of biological signals and images. System descriptions are welcome if they illustrate and substantiate the underlying methodology that is the principal focus of the report and an effort is made to address the generalizability and/or range of application of that methodology. Note also that, given the international nature of JBI, papers that deal with specific languages other than English, or with country-specific health systems or approaches, are acceptable for JBI only if they offer generalizable lessons that are relevant to the broad JBI readership, regardless of their country, language, culture, or health system.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


