{"title":"疾病亚型的自动注释","authors":"Dan Ofer, Michal Linial","doi":"10.1016/j.jbi.2024.104650","DOIUrl":null,"url":null,"abstract":"<div><h3>Background</h3><p>Distinguishing diseases into distinct subtypes is crucial for study and effective treatment strategies. The Open Targets Platform (OT) integrates biomedical, genetic, and biochemical datasets to empower disease ontologies, classifications, and potential gene targets. Nevertheless, many disease annotations are incomplete, requiring laborious expert medical input. This challenge is especially pronounced for rare and orphan diseases, where resources are scarce.</p></div><div><h3>Methods</h3><p>We present a machine learning approach to identifying diseases with potential subtypes, using the approximately 23,000 diseases documented in OT. We derive novel features for predicting diseases with subtypes using direct evidence. Machine learning models were applied to analyze feature importance and evaluate predictive performance for discovering both known and novel disease subtypes.</p></div><div><h3>Results</h3><p>Our model achieves a high (89.4%) ROC AUC (Area Under the Receiver Operating Characteristic Curve) in identifying known disease subtypes. We integrated pre-trained deep-learning language models and showed their benefits. Moreover, we identify 515 disease candidates predicted to possess previously unannotated subtypes.</p></div><div><h3>Conclusions</h3><p>Our models can partition diseases into distinct subtypes. This methodology enables a robust, scalable approach for improving knowledge-based annotations and a comprehensive assessment of disease ontology tiers. Our candidates are attractive targets for further study and personalized medicine, potentially aiding in the unveiling of new therapeutic indications for sought-after targets.</p></div>","PeriodicalId":15263,"journal":{"name":"Journal of Biomedical Informatics","volume":"154 ","pages":"Article 104650"},"PeriodicalIF":4.0000,"publicationDate":"2024-05-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S1532046424000686/pdfft?md5=2a780c6c20882fa8a92e8fd6785f441b&pid=1-s2.0-S1532046424000686-main.pdf","citationCount":"0","resultStr":"{\"title\":\"Automated annotation of disease subtypes\",\"authors\":\"Dan Ofer, Michal Linial\",\"doi\":\"10.1016/j.jbi.2024.104650\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><h3>Background</h3><p>Distinguishing diseases into distinct subtypes is crucial for study and effective treatment strategies. The Open Targets Platform (OT) integrates biomedical, genetic, and biochemical datasets to empower disease ontologies, classifications, and potential gene targets. Nevertheless, many disease annotations are incomplete, requiring laborious expert medical input. This challenge is especially pronounced for rare and orphan diseases, where resources are scarce.</p></div><div><h3>Methods</h3><p>We present a machine learning approach to identifying diseases with potential subtypes, using the approximately 23,000 diseases documented in OT. We derive novel features for predicting diseases with subtypes using direct evidence. Machine learning models were applied to analyze feature importance and evaluate predictive performance for discovering both known and novel disease subtypes.</p></div><div><h3>Results</h3><p>Our model achieves a high (89.4%) ROC AUC (Area Under the Receiver Operating Characteristic Curve) in identifying known disease subtypes. We integrated pre-trained deep-learning language models and showed their benefits. Moreover, we identify 515 disease candidates predicted to possess previously unannotated subtypes.</p></div><div><h3>Conclusions</h3><p>Our models can partition diseases into distinct subtypes. This methodology enables a robust, scalable approach for improving knowledge-based annotations and a comprehensive assessment of disease ontology tiers. Our candidates are attractive targets for further study and personalized medicine, potentially aiding in the unveiling of new therapeutic indications for sought-after targets.</p></div>\",\"PeriodicalId\":15263,\"journal\":{\"name\":\"Journal of Biomedical Informatics\",\"volume\":\"154 \",\"pages\":\"Article 104650\"},\"PeriodicalIF\":4.0000,\"publicationDate\":\"2024-05-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.sciencedirect.com/science/article/pii/S1532046424000686/pdfft?md5=2a780c6c20882fa8a92e8fd6785f441b&pid=1-s2.0-S1532046424000686-main.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Biomedical Informatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S1532046424000686\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Informatics","FirstCategoryId":"3","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1532046424000686","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
摘要
背景将疾病分为不同的亚型对研究和有效的治疗策略至关重要。开放靶点平台(OT)整合了生物医学、遗传学和生物化学数据集,以增强疾病本体、分类和潜在基因靶点的能力。然而,许多疾病注释并不完整,需要专家费力地输入医学信息。我们提出了一种机器学习方法,利用 OT 中记录的约 23,000 种疾病来识别具有潜在亚型的疾病。我们利用直接证据得出了预测疾病亚型的新特征。结果我们的模型在识别已知疾病亚型方面达到了很高(89.4%)的 ROC AUC(接收者工作特征曲线下面积)。我们整合了预先训练的深度学习语言模型,并展示了其优势。此外,我们还确定了 515 种候选疾病,预测它们具有以前未注明的亚型。我们的模型可以将疾病划分为不同的亚型,这种方法是改进基于知识的注释和全面评估疾病本体层级的一种稳健、可扩展的方法。我们的候选目标对进一步研究和个性化医疗很有吸引力,可能有助于揭示热门目标的新治疗适应症。
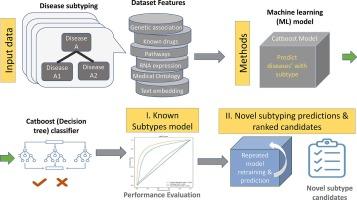
Distinguishing diseases into distinct subtypes is crucial for study and effective treatment strategies. The Open Targets Platform (OT) integrates biomedical, genetic, and biochemical datasets to empower disease ontologies, classifications, and potential gene targets. Nevertheless, many disease annotations are incomplete, requiring laborious expert medical input. This challenge is especially pronounced for rare and orphan diseases, where resources are scarce.
Methods
We present a machine learning approach to identifying diseases with potential subtypes, using the approximately 23,000 diseases documented in OT. We derive novel features for predicting diseases with subtypes using direct evidence. Machine learning models were applied to analyze feature importance and evaluate predictive performance for discovering both known and novel disease subtypes.
Results
Our model achieves a high (89.4%) ROC AUC (Area Under the Receiver Operating Characteristic Curve) in identifying known disease subtypes. We integrated pre-trained deep-learning language models and showed their benefits. Moreover, we identify 515 disease candidates predicted to possess previously unannotated subtypes.
Conclusions
Our models can partition diseases into distinct subtypes. This methodology enables a robust, scalable approach for improving knowledge-based annotations and a comprehensive assessment of disease ontology tiers. Our candidates are attractive targets for further study and personalized medicine, potentially aiding in the unveiling of new therapeutic indications for sought-after targets.
期刊介绍:
The Journal of Biomedical Informatics reflects a commitment to high-quality original research papers, reviews, and commentaries in the area of biomedical informatics methodology. Although we publish articles motivated by applications in the biomedical sciences (for example, clinical medicine, health care, population health, and translational bioinformatics), the journal emphasizes reports of new methodologies and techniques that have general applicability and that form the basis for the evolving science of biomedical informatics. Articles on medical devices; evaluations of implemented systems (including clinical trials of information technologies); or papers that provide insight into a biological process, a specific disease, or treatment options would generally be more suitable for publication in other venues. Papers on applications of signal processing and image analysis are often more suitable for biomedical engineering journals or other informatics journals, although we do publish papers that emphasize the information management and knowledge representation/modeling issues that arise in the storage and use of biological signals and images. System descriptions are welcome if they illustrate and substantiate the underlying methodology that is the principal focus of the report and an effort is made to address the generalizability and/or range of application of that methodology. Note also that, given the international nature of JBI, papers that deal with specific languages other than English, or with country-specific health systems or approaches, are acceptable for JBI only if they offer generalizable lessons that are relevant to the broad JBI readership, regardless of their country, language, culture, or health system.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


