{"title":"基于表征约束的人脸反欺骗双通道网络","authors":"Zuhe Li, Yuhao Cui, Fengqin Wang, Weihua Liu, Yongshuang Yang, Zeqi Yu, Bin Jiang, Hui Chen","doi":"10.1049/cvi2.12245","DOIUrl":null,"url":null,"abstract":"<p>Although multimodal face data have obvious advantages in describing live and spoofed features, single-modality face antispoofing technologies are still widely used when it is difficult to obtain multimodal face images or inconvenient to integrate and deploy multimodal sensors. Since the live/spoofed representations in visible light facial images include considerable face identity information interference, existing deep learning-based face antispoofing models achieve poor performance when only the visible light modality is used. To address the above problems, the authors design a dual-channel network structure and a constrained representation learning method for face antispoofing. First, they design a dual-channel attention mechanism-based grouped convolutional neural network (CNN) to learn important deceptive cues in live and spoofed faces. Second, they design inner contrastive estimation-based representation constraints for both live and spoofed samples to minimise the sample similarity loss to prevent the CNN from learning more facial appearance information. This increases the distance between live and spoofed faces and enhances the network's ability to identify deceptive cues. The evaluation results indicate that the framework we designed achieves an average classification error rate (ACER) of 2.37% on the visible light modality subset of the CASIA-SURF dataset and an ACER of 2.4% on the CASIA-SURF CeFA dataset, outperforming existing methods. The proposed method achieves low ACER scores in cross-dataset testing, demonstrating its advantage in domain generalisation.</p>","PeriodicalId":56304,"journal":{"name":"IET Computer Vision","volume":"18 2","pages":"289-303"},"PeriodicalIF":1.5000,"publicationDate":"2023-10-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1049/cvi2.12245","citationCount":"0","resultStr":"{\"title\":\"Representation constraint-based dual-channel network for face antispoofing\",\"authors\":\"Zuhe Li, Yuhao Cui, Fengqin Wang, Weihua Liu, Yongshuang Yang, Zeqi Yu, Bin Jiang, Hui Chen\",\"doi\":\"10.1049/cvi2.12245\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Although multimodal face data have obvious advantages in describing live and spoofed features, single-modality face antispoofing technologies are still widely used when it is difficult to obtain multimodal face images or inconvenient to integrate and deploy multimodal sensors. Since the live/spoofed representations in visible light facial images include considerable face identity information interference, existing deep learning-based face antispoofing models achieve poor performance when only the visible light modality is used. To address the above problems, the authors design a dual-channel network structure and a constrained representation learning method for face antispoofing. First, they design a dual-channel attention mechanism-based grouped convolutional neural network (CNN) to learn important deceptive cues in live and spoofed faces. Second, they design inner contrastive estimation-based representation constraints for both live and spoofed samples to minimise the sample similarity loss to prevent the CNN from learning more facial appearance information. This increases the distance between live and spoofed faces and enhances the network's ability to identify deceptive cues. The evaluation results indicate that the framework we designed achieves an average classification error rate (ACER) of 2.37% on the visible light modality subset of the CASIA-SURF dataset and an ACER of 2.4% on the CASIA-SURF CeFA dataset, outperforming existing methods. The proposed method achieves low ACER scores in cross-dataset testing, demonstrating its advantage in domain generalisation.</p>\",\"PeriodicalId\":56304,\"journal\":{\"name\":\"IET Computer Vision\",\"volume\":\"18 2\",\"pages\":\"289-303\"},\"PeriodicalIF\":1.5000,\"publicationDate\":\"2023-10-10\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1049/cvi2.12245\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"IET Computer Vision\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1049/cvi2.12245\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q4\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"IET Computer Vision","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1049/cvi2.12245","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Representation constraint-based dual-channel network for face antispoofing
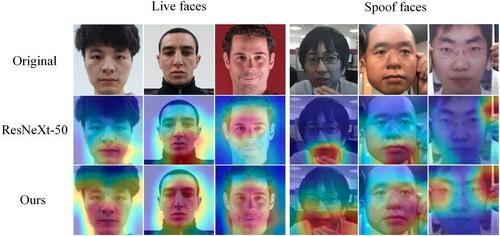
Although multimodal face data have obvious advantages in describing live and spoofed features, single-modality face antispoofing technologies are still widely used when it is difficult to obtain multimodal face images or inconvenient to integrate and deploy multimodal sensors. Since the live/spoofed representations in visible light facial images include considerable face identity information interference, existing deep learning-based face antispoofing models achieve poor performance when only the visible light modality is used. To address the above problems, the authors design a dual-channel network structure and a constrained representation learning method for face antispoofing. First, they design a dual-channel attention mechanism-based grouped convolutional neural network (CNN) to learn important deceptive cues in live and spoofed faces. Second, they design inner contrastive estimation-based representation constraints for both live and spoofed samples to minimise the sample similarity loss to prevent the CNN from learning more facial appearance information. This increases the distance between live and spoofed faces and enhances the network's ability to identify deceptive cues. The evaluation results indicate that the framework we designed achieves an average classification error rate (ACER) of 2.37% on the visible light modality subset of the CASIA-SURF dataset and an ACER of 2.4% on the CASIA-SURF CeFA dataset, outperforming existing methods. The proposed method achieves low ACER scores in cross-dataset testing, demonstrating its advantage in domain generalisation.
期刊介绍:
IET Computer Vision seeks original research papers in a wide range of areas of computer vision. The vision of the journal is to publish the highest quality research work that is relevant and topical to the field, but not forgetting those works that aim to introduce new horizons and set the agenda for future avenues of research in computer vision.
IET Computer Vision welcomes submissions on the following topics:
Biologically and perceptually motivated approaches to low level vision (feature detection, etc.);
Perceptual grouping and organisation
Representation, analysis and matching of 2D and 3D shape
Shape-from-X
Object recognition
Image understanding
Learning with visual inputs
Motion analysis and object tracking
Multiview scene analysis
Cognitive approaches in low, mid and high level vision
Control in visual systems
Colour, reflectance and light
Statistical and probabilistic models
Face and gesture
Surveillance
Biometrics and security
Robotics
Vehicle guidance
Automatic model aquisition
Medical image analysis and understanding
Aerial scene analysis and remote sensing
Deep learning models in computer vision
Both methodological and applications orientated papers are welcome.
Manuscripts submitted are expected to include a detailed and analytical review of the literature and state-of-the-art exposition of the original proposed research and its methodology, its thorough experimental evaluation, and last but not least, comparative evaluation against relevant and state-of-the-art methods. Submissions not abiding by these minimum requirements may be returned to authors without being sent to review.
Special Issues Current Call for Papers:
Computer Vision for Smart Cameras and Camera Networks - https://digital-library.theiet.org/files/IET_CVI_SC.pdf
Computer Vision for the Creative Industries - https://digital-library.theiet.org/files/IET_CVI_CVCI.pdf

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


