Qing Lyu, Josh Tan, Michael E Zapadka, Janardhana Ponnatapura, Chuang Niu, Kyle J Myers, Ge Wang, Christopher T Whitlow
{"title":"Translating radiology reports into plain language using ChatGPT and GPT-4 with prompt learning: results, limitations, and potential.","authors":"Qing Lyu, Josh Tan, Michael E Zapadka, Janardhana Ponnatapura, Chuang Niu, Kyle J Myers, Ge Wang, Christopher T Whitlow","doi":"10.1186/s42492-023-00136-5","DOIUrl":null,"url":null,"abstract":"<p><p>The large language model called ChatGPT has drawn extensively attention because of its human-like expression and reasoning abilities. In this study, we investigate the feasibility of using ChatGPT in experiments on translating radiology reports into plain language for patients and healthcare providers so that they are educated for improved healthcare. Radiology reports from 62 low-dose chest computed tomography lung cancer screening scans and 76 brain magnetic resonance imaging metastases screening scans were collected in the first half of February for this study. According to the evaluation by radiologists, ChatGPT can successfully translate radiology reports into plain language with an average score of 4.27 in the five-point system with 0.08 places of information missing and 0.07 places of misinformation. In terms of the suggestions provided by ChatGPT, they are generally relevant such as keeping following-up with doctors and closely monitoring any symptoms, and for about 37% of 138 cases in total ChatGPT offers specific suggestions based on findings in the report. ChatGPT also presents some randomness in its responses with occasionally over-simplified or neglected information, which can be mitigated using a more detailed prompt. Furthermore, ChatGPT results are compared with a newly released large model GPT-4, showing that GPT-4 can significantly improve the quality of translated reports. Our results show that it is feasible to utilize large language models in clinical education, and further efforts are needed to address limitations and maximize their potential.</p>","PeriodicalId":52384,"journal":{"name":"Visual Computing for Industry, Biomedicine, and Art","volume":"6 1","pages":"9"},"PeriodicalIF":6.0000,"publicationDate":"2023-05-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10192466/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Visual Computing for Industry, Biomedicine, and Art","FirstCategoryId":"1093","ListUrlMain":"https://doi.org/10.1186/s42492-023-00136-5","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"Arts and Humanities","Score":null,"Total":0}
引用次数: 0
Abstract
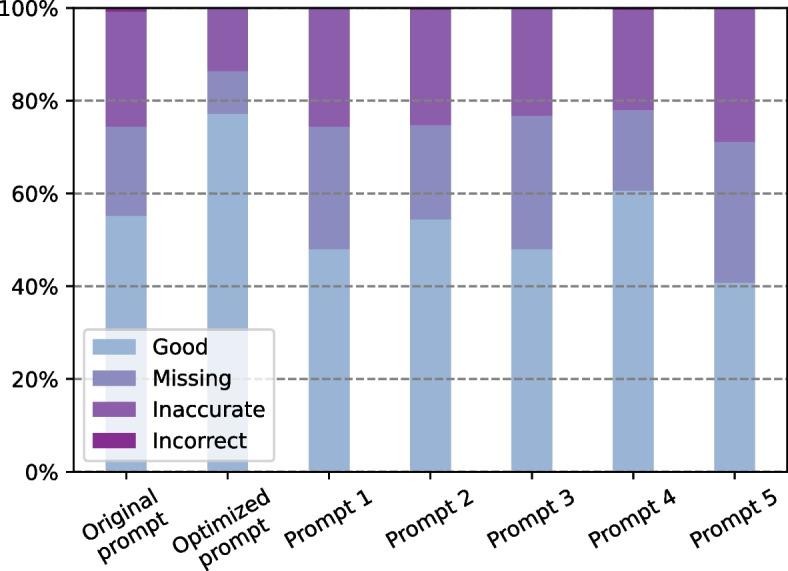
The large language model called ChatGPT has drawn extensively attention because of its human-like expression and reasoning abilities. In this study, we investigate the feasibility of using ChatGPT in experiments on translating radiology reports into plain language for patients and healthcare providers so that they are educated for improved healthcare. Radiology reports from 62 low-dose chest computed tomography lung cancer screening scans and 76 brain magnetic resonance imaging metastases screening scans were collected in the first half of February for this study. According to the evaluation by radiologists, ChatGPT can successfully translate radiology reports into plain language with an average score of 4.27 in the five-point system with 0.08 places of information missing and 0.07 places of misinformation. In terms of the suggestions provided by ChatGPT, they are generally relevant such as keeping following-up with doctors and closely monitoring any symptoms, and for about 37% of 138 cases in total ChatGPT offers specific suggestions based on findings in the report. ChatGPT also presents some randomness in its responses with occasionally over-simplified or neglected information, which can be mitigated using a more detailed prompt. Furthermore, ChatGPT results are compared with a newly released large model GPT-4, showing that GPT-4 can significantly improve the quality of translated reports. Our results show that it is feasible to utilize large language models in clinical education, and further efforts are needed to address limitations and maximize their potential.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


