Comparative analysis of speaker identification performance using deep learning, machine learning, and novel subspace classifiers with multiple feature extraction techniques
IF 2.9
3区 工程技术
Q2 ENGINEERING, ELECTRICAL & ELECTRONIC
引用次数: 0
Abstract
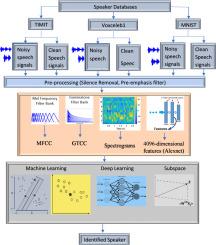
Speaker identification is vital in various application domains, such as automation, security, and enhancing user experience. In the literature, convolutional neural network (CNN) or recurrent neural network (RNN) classifiers are generally used due to the one-dimensional time series of speech signals. However, new approaches using subspace classifiers are also crucial in speaker identification. In this study, in addition to the newly developed subspace classifiers for speaker identification, traditional classification algorithms, and various hybrid algorithms are analyzed in terms of performance. Stacked Features-Common Vector Approach (SF-CVA) and Hybrid CVA-Fisher Linear Discriminant Analysis (HCF) subspace classifiers are used for speaker identification for the first time in the literature. In addition, CVA is evaluated for the first time for speaker identification using hybrid deep learning algorithms. The study includes Recurrent Neural Network-Long Short-Term Memory (RNN-LSTM), i-vector + Probabilistic Linear Discriminant Analysis (i-vector+PLDA), Time Delayed Neural Network (TDNN), AutoEncoder+Softmax (AE+Softmax), K-Nearest Neighbors (KNN), Support Vector Machine (SVM), Common Vector Approach (CVA), SF-CVA, HCF, and Alexnet classifiers for speaker identification. This study uses MNIST, TIMIT and Voxceleb1 databases for clean and noisy speech signals. Six different feature structures are tested in the study. The six different feature extraction approaches consist of Mel Frequency Cepstral Coefficients (MFCC)+Pitch, Gammatone Filter Bank Cepstral Coefficients (GTCC)+Pitch, MFCC+GTCC+Pitch+seven spectral features, spectrograms,i-vectors, and Alexnet feature vectors. High accuracy rates were obtained, especially in tests using SF-CVA. RNN-LSTM, i-vector+KNN, AE+Softmax, TDNN, and i-vector+HCF classifiers also gave high test accuracy rates.
使用深度学习、机器学习和新型子空间分类器以及多种特征提取技术的扬声器识别性能对比分析
在自动化、安全和提升用户体验等多个应用领域,说话人识别都至关重要。由于语音信号是一维时间序列,因此文献中通常使用卷积神经网络(CNN)或递归神经网络(RNN)分类器。然而,使用子空间分类器的新方法对于扬声器识别也至关重要。在本研究中,除了新开发的用于扬声器识别的子空间分类器外,还分析了传统分类算法和各种混合算法的性能。堆叠特征-通用向量法(SF-CVA)和混合 CVA-费舍线性判别分析(HCF)子空间分类器在文献中首次用于说话人识别。此外,还首次评估了使用混合深度学习算法进行说话人识别的 CVA。该研究包括用于识别说话人的递归神经网络-长短期记忆(RNN-LSTM)、i-vector + 概率线性判别分析(i-vector+PLDA)、延时神经网络(TDNN)、自动编码器+软最大值(AE+Softmax)、K-近邻(KNN)、支持向量机(SVM)、共向量方法(CVA)、SF-CVA、HCF 和 Alexnet 分类器。本研究使用 MNIST、TIMIT 和 Voxceleb1 数据库来处理干净和有噪声的语音信号。研究中测试了六种不同的特征结构。这六种不同的特征提取方法包括 Mel Frequency Cepstral Coefficients (MFCC)+Pitch, Gammatone Filter Bank Cepstral Coefficients (GTCC)+Pitch, MFCC+GTCC+Pitch+seven spectral features, spectrograms, i-vectors, 和 Alexnet feature vectors。特别是在使用 SF-CVA 的测试中,获得了很高的准确率。RNN-LSTM、i-vector+KNN、AE+Softmax、TDNN 和 i-vector+HCF分类器的测试准确率也很高。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Digital Signal Processing
工程技术-工程:电子与电气
CiteScore
5.30
自引率
17.20%
发文量
435
审稿时长
66 days
期刊介绍:
Digital Signal Processing: A Review Journal is one of the oldest and most established journals in the field of signal processing yet it aims to be the most innovative. The Journal invites top quality research articles at the frontiers of research in all aspects of signal processing. Our objective is to provide a platform for the publication of ground-breaking research in signal processing with both academic and industrial appeal.
The journal has a special emphasis on statistical signal processing methodology such as Bayesian signal processing, and encourages articles on emerging applications of signal processing such as:
• big data• machine learning• internet of things• information security• systems biology and computational biology,• financial time series analysis,• autonomous vehicles,• quantum computing,• neuromorphic engineering,• human-computer interaction and intelligent user interfaces,• environmental signal processing,• geophysical signal processing including seismic signal processing,• chemioinformatics and bioinformatics,• audio, visual and performance arts,• disaster management and prevention,• renewable energy,
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


