{"title":"An automated approach for binary classification on imbalanced data","authors":"Pedro Marques Vieira, Fátima Rodrigues","doi":"10.1007/s10115-023-02046-7","DOIUrl":null,"url":null,"abstract":"<p>Imbalanced data are present in various business sectors and must be handled with the proper resampling methods and classification algorithms. To handle imbalanced data, there are numerous resampling and learning method combinations; nonetheless, their effective use necessitates specialised knowledge. In this paper, several approaches, ranging from more accessible to more advanced in the domain of data resampling techniques, will be considered to handle imbalanced data. The application developed delivers recommendations of the most suitable combinations of techniques for a specific dataset by extracting and comparing dataset meta-feature values recorded in a knowledge base. It facilitates effortless classification and automates part of the machine learning pipeline with comparable or better results than state-of-the-art solutions and with a much smaller execution time.\n</p>","PeriodicalId":54749,"journal":{"name":"Knowledge and Information Systems","volume":"16 1","pages":""},"PeriodicalIF":2.5000,"publicationDate":"2024-01-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Knowledge and Information Systems","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10115-023-02046-7","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
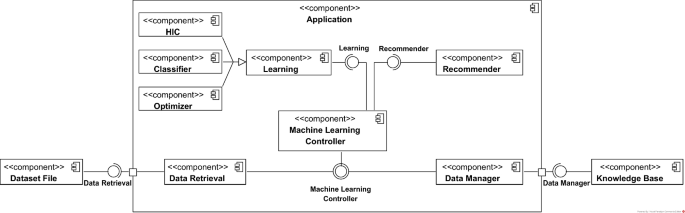
Imbalanced data are present in various business sectors and must be handled with the proper resampling methods and classification algorithms. To handle imbalanced data, there are numerous resampling and learning method combinations; nonetheless, their effective use necessitates specialised knowledge. In this paper, several approaches, ranging from more accessible to more advanced in the domain of data resampling techniques, will be considered to handle imbalanced data. The application developed delivers recommendations of the most suitable combinations of techniques for a specific dataset by extracting and comparing dataset meta-feature values recorded in a knowledge base. It facilitates effortless classification and automates part of the machine learning pipeline with comparable or better results than state-of-the-art solutions and with a much smaller execution time.
期刊介绍:
Knowledge and Information Systems (KAIS) provides an international forum for researchers and professionals to share their knowledge and report new advances on all topics related to knowledge systems and advanced information systems. This monthly peer-reviewed archival journal publishes state-of-the-art research reports on emerging topics in KAIS, reviews of important techniques in related areas, and application papers of interest to a general readership.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


