KC-GEE: knowledge-based conditioning for generative event extraction
IF 3.4
3区 计算机科学
Q2 COMPUTER SCIENCE, INFORMATION SYSTEMS
World Wide Web-Internet and Web Information Systems
Pub Date : 2023-10-25
DOI:10.1007/s11280-023-01216-5
引用次数: 1
Abstract
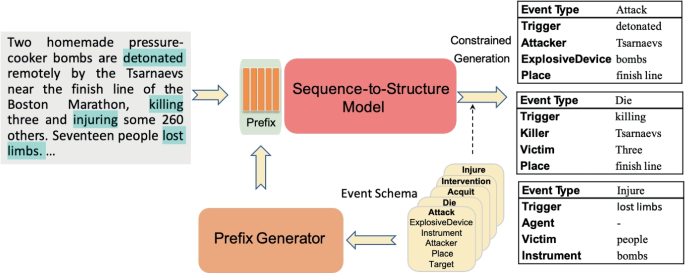
Abstract Event extraction is an important, but challenging task. Many existing techniques decompose it into event and argument detection/classification subtasks, which are complex structured prediction problems. Generation-based extraction techniques lessen the complexity of the problem formulation and are able to leverage the reasoning capabilities of large pretrained language models. However, they still suffer from poor zero-shot generalizability and are ineffective in handling long contexts such as documents. We propose a generative event extraction model, KC-GEE, that addresses these limitations. A key contribution of KC-GEE is a novel knowledge-based conditioning technique that injects the schema of candidate event types as the prefix into each layer of an encoder-decoder language model. This enables effective zero-shot learning and improves supervised learning. Our experiments on two benchmark datasets demonstrate the strong performance of our KC-GEE model. It achieves particularly strong results in the challenging document-level extraction task and in the zero-shot learning setting, outperforming state-of-the-art models by up to 5.4 absolute F1 points.
KC-GEE:基于知识的条件作用生成事件提取
摘要事件提取是一项重要但具有挑战性的任务。许多现有技术将其分解为事件和参数检测/分类子任务,这是复杂的结构化预测问题。基于生成的提取技术降低了问题表述的复杂性,并且能够利用大型预训练语言模型的推理能力。然而,它们仍然存在较差的零概率通用性,并且在处理文档等长上下文时效果不佳。我们提出了一个生成事件提取模型,KC-GEE,解决了这些限制。KC-GEE的一个关键贡献是一种新的基于知识的条件反射技术,它将候选事件类型的模式作为前缀注入到编码器-解码器语言模型的每一层。这使得有效的零射击学习和改进监督学习成为可能。我们在两个基准数据集上的实验证明了我们的KC-GEE模型的强大性能。它在具有挑战性的文档级提取任务和零射击学习设置中取得了特别强大的结果,比最先进的模型高出5.4个绝对F1点。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

World Wide Web-Internet and Web Information Systems
工程技术-计算机:软件工程
CiteScore
7.30
自引率
10.80%
发文量
131
审稿时长
6 months
期刊介绍:
World Wide Web: Internet and Web Information Systems (WWW) is an international, archival, peer-reviewed journal which covers all aspects of the World Wide Web, including issues related to architectures, applications, Internet and Web information systems, and communities. The purpose of this journal is to provide an international forum for researchers, professionals, and industrial practitioners to share their rapidly developing knowledge and report on new advances in Internet and web-based systems. The journal also focuses on all database- and information-system topics that relate to the Internet and the Web, particularly on ways to model, design, develop, integrate, and manage these systems.
Appearing quarterly, the journal publishes (1) papers describing original ideas and new results, (2) vision papers, (3) reviews of important techniques in related areas, (4) innovative application papers, and (5) progress reports on major international research projects. Papers published in the WWW journal deal with subjects directly or indirectly related to the World Wide Web. The WWW journal provides timely, in-depth coverage of the most recent developments in the World Wide Web discipline to enable anyone involved to keep up-to-date with this dynamically changing technology.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


